하다하다 init weight 논문까지..
init만 있는줄 알았는데 activation까지 -_-;;;;
weight init의 중요성
사실 이게 중요한 이유가, 같은 model에 같은 optimizer를 사용하더라도 성능이 천차만별이며,
심지어 훈련에 실패하기도 한다.
그럼에도 우리는 이 부분에 대해서 잘 생각하지 않고 사용하는 이유는..
대부분의 deep learning toolkit에서 default로 좋은 성능을 보여주는 weight를 설정하고 있기 때문이다.
그럼에도,
무엇이든 그러하게도,
어떤 조합을 하느냐에 따라서 default가 훈련여부를 가를 수 있다.
중요성은 이정도면 됐고,
내용으로 들어가보자.
기존 방식
he 제안방식
he는 resnet 제안한 녀석으로 relu를 엄청 많이 넣다보니, relu에 따른 init에 대한 고민을 많이 한 것 같다.
예전에도 이러한 init에 대한 논문은 MS에서도 나온적이 있었다.
암튼 이들이 주목한 것은 resnet과 상관이 있다.
relu도 많이 넣으면서 layer를 무지 깊게 갔더니,
어느 순간 기본의 Xavier 방식이 성능이 떨어지는 수준이 아니라,
훈련이 안되는 경우들이 발생한다는 것이다.
논문에서는 30 layer를 실험 결과로 포함하고 있다.
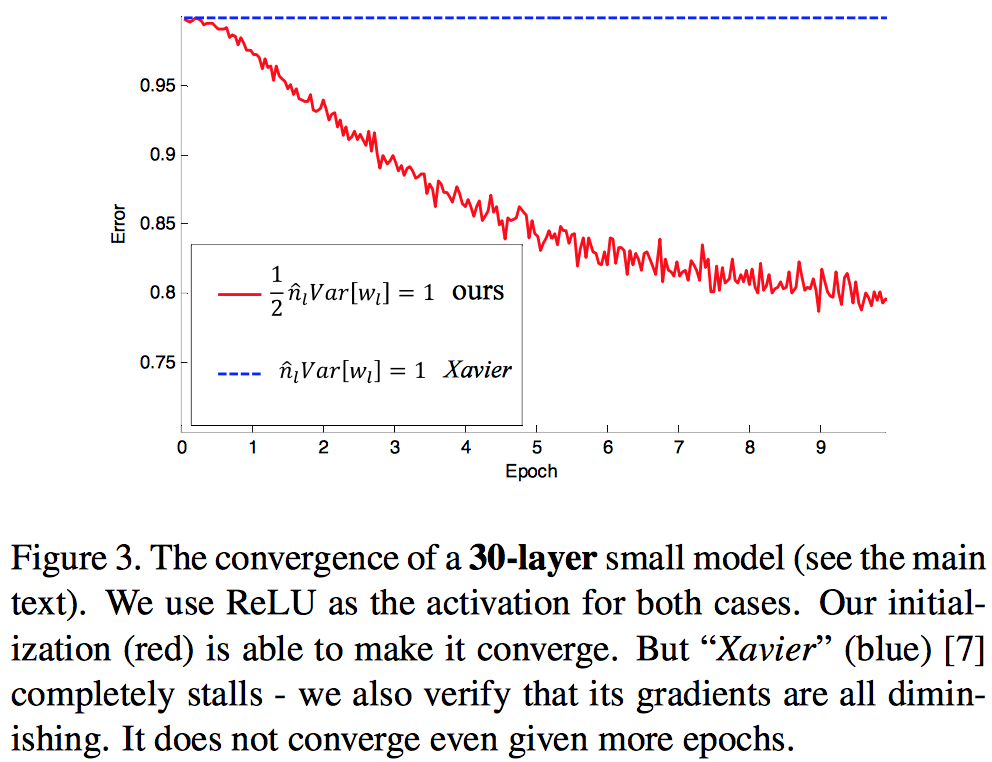
이것보다 적은 layer에서도 훈련이 되긴 하지만 성능이 떨어지는 것을 확인하였다.
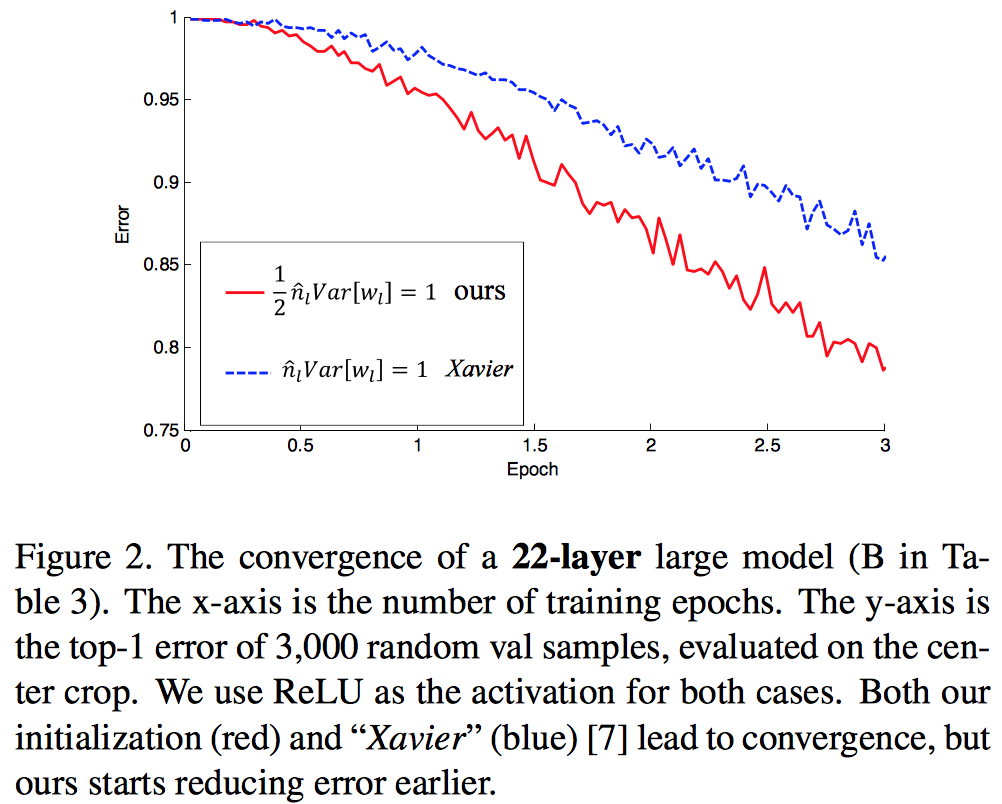
최종적으로는 PRelu (Parametric Relu)를 포함하여 성능이 향상되었다고 하고 있지만,
Relu 에서도 성능은 좋은 것으로 보인다. 그리고 실제로 resnet에 relu를 사용하기도 했고…
정리
위에서 소개한 내용을 보면, 이러한 경우들이 발생하긴 한다고 하지만, fine-tuning하는 입장에서 고려할 사항으로 보인다.
그 전에 feasibility를 보는 입장이라고 하면 이러한 내용은 우선은 무시하고 넘어가더라도 크게 무리는 없을 것으로 보인다.
오히려 처음 접근할 때는 이런 내용보다는 nuts and bolt에 소개된 내용 같은 것들이 더 의미있다고 볼 수 있을 것 같다.