링크는…
Keras - advanced activations layer
Activation
예전에 machine learning 수업을 들을 때만 해도 sigmoid function과 tanh 만 있는 줄 알았다.
그런데 요즘에 보면 Relu는 기본이오,
LeakRelu나 등등 참 많은 activation이 소개되고 있다. 이거에 따라서 regularization이 되기도 하고, 아니기도 하고,
심지어 학습 정도까지 차이를 가지게 된다.
그런 점에서 보면
지원하는 activation
지원하는 advanced activation은 다음과 같다.
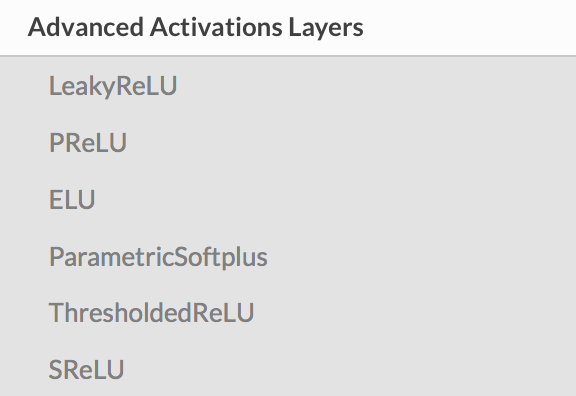
보면 2015년 이후로 제안된 방식 중에 좀 알려진 activation들이 advanced tap에 들어와 있는 것으로 보인다.
하아..
이걸 언제 다 보지 싶네…. 떱..
참고로 일반 activation은 아래 링크에서 참고하면 된다.
Keras - core layer, activation

일부 간단 설명
LeakyRelu
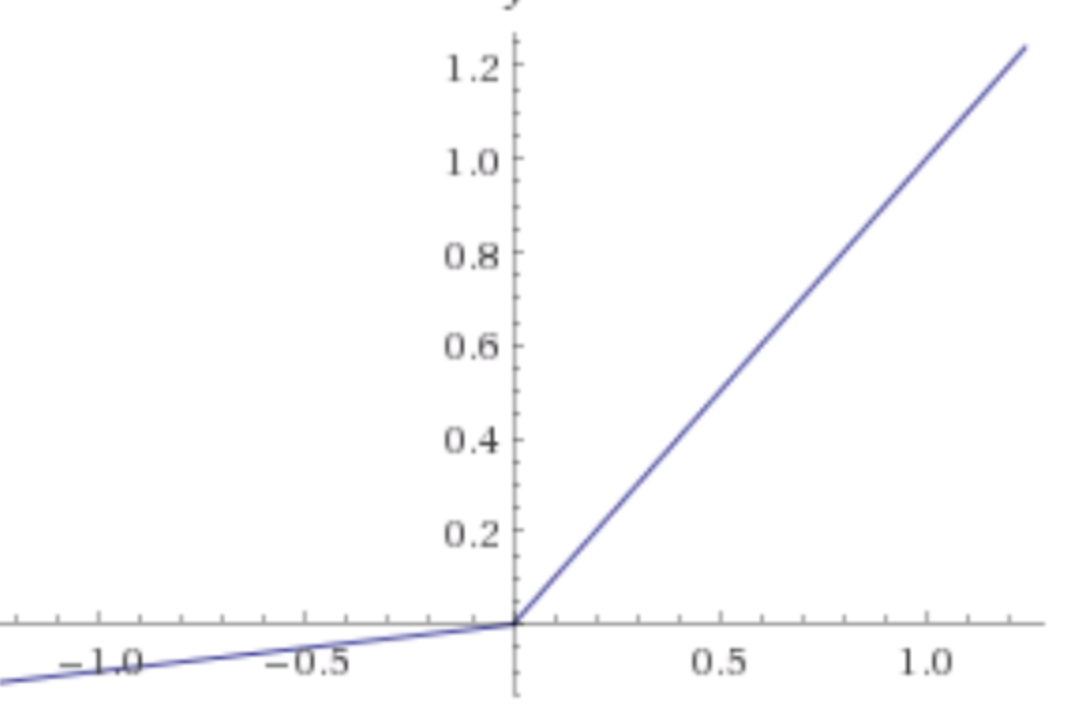
모양새는 다음과 같다.
relu 다음으로 (시간상으로…) 유명한 activation이고,
실제로 성능이 괜찮다는 이야기들이 많이 나온다.
다만, 직접 경험해보진 못해서..
아직까지 돌리는 task에서 leakyRelu에 까지 고려하진 않았다.
relu와 유사한 형태지만 0 이하에 대해서 0으로 자르는 것이 아니라 작은 값을 가지도록 하는 것이 특징이다.
이에 대한 형식을 아래와 같다.
keras.layers.advanced_activations.LeakyReLU(alpha=0.3)
PRelu

모양새는 LeakyRelu랑 같다. 같은데, 다만…
기존에 LeakyRelu는 0 이하의 영역에 해당하는 기울기가 hyper-parameter로 fixed된 값이 사용되지만,
PRelu에서는 이 기울기 \(\alpha\)를 학습을 통해서 얻게 되는 것이다.
그래서 이름이 Parametric Relu..
형태는 다음과 같다.
keras.layers.advanced_activations.PReLU(init='zero', weights=None, shared_axes=None)
정리
생각보다 많은 activation이 제안되고 있다.
그럼에도 우리는 여전히 Relu를 (너무) 많이 사랑하는 것 아닌가 싶다.
논문을 하나씩 정리하면서 실제 성능도 비교해봐야겠다.