One shot learning?
말그대로 하나만 딱 돌려서 클래스에 대한 분류를 완성한다는 의미이다.
조금은 큰 범위로 봐서 클래스별 1장이 아니라 5장이나 소수의 몇 장 정도로 이야기하기도 한다.
본 논문은?
one shot learning을 하는데 있어서 필요한 extractor (feature extractor)를 neural network로 하겠다는 취지다.
다양한 one shot learning 기법들이 있긴한데, 여기서는 extractor를 matching network라는 이름으로 정의하고,
그에 대한 내용을 설명하고 있다고 보면 되겠다.
목차
- Introduction
- Model
- Abstract explanation
Related work- Experiments
- Omniglot
- ImageNet (modified)
Language model
- Conclusion
- Appendix
- Model in detail
Intro
One shot learning에 어울리는 기존 방식은? -> nearest neighbors (kNN)
MANN, metric learning도 있음. (자세한 설명은 3장)
- matching networks
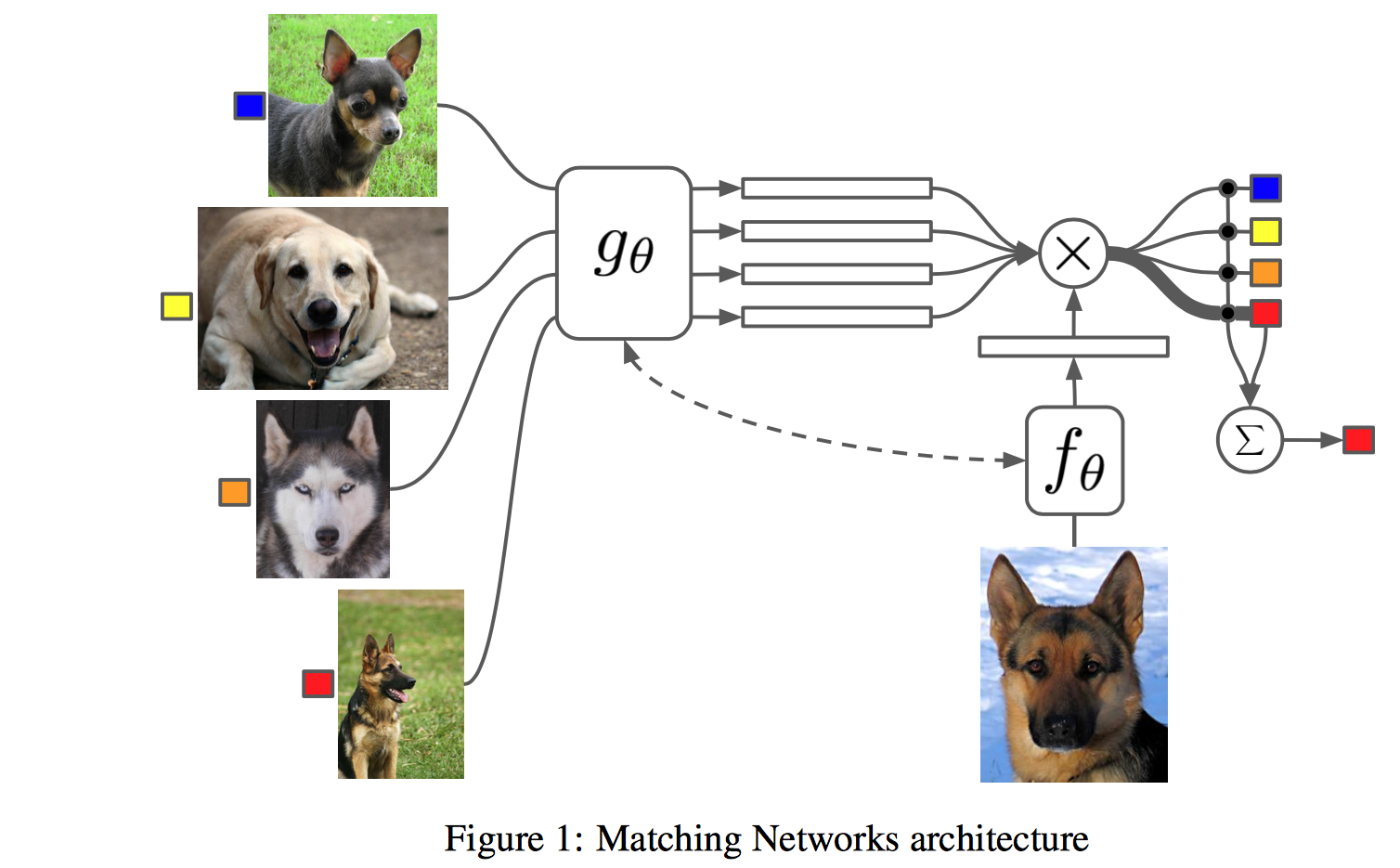 \(f_{\theta}\)와 \(g_{\theta}\)를 이용하여 가장 적합한 클래스를 찾는 것
\(f_{\theta}\)와 \(g_{\theta}\)를 이용하여 가장 적합한 클래스를 찾는 것
Notation
\(x, y\) : 훈련에 사용한 클래스의 입력과 그의 label
\(\hat{x}, \hat{y}\) : 훈련에 사용하지 않은 클래스의 입력과 그의 label
\(S\): 훈련에 사용하는 데이터셋의 집합
\(S`\): 훈련에 사용하지 않는 데이터셋의 집합
\(B\): 훈련에 사용하는 데이터셋의 batch-set
\(k\): 훈련에 사용하는 클래스의 수
\(c()\): cosine similarity function
전체적으로 돌아가는 방법
- Training set을 구성한다.
- Training set으로 부터 support set \(S\)과 batch set을 생성한다.
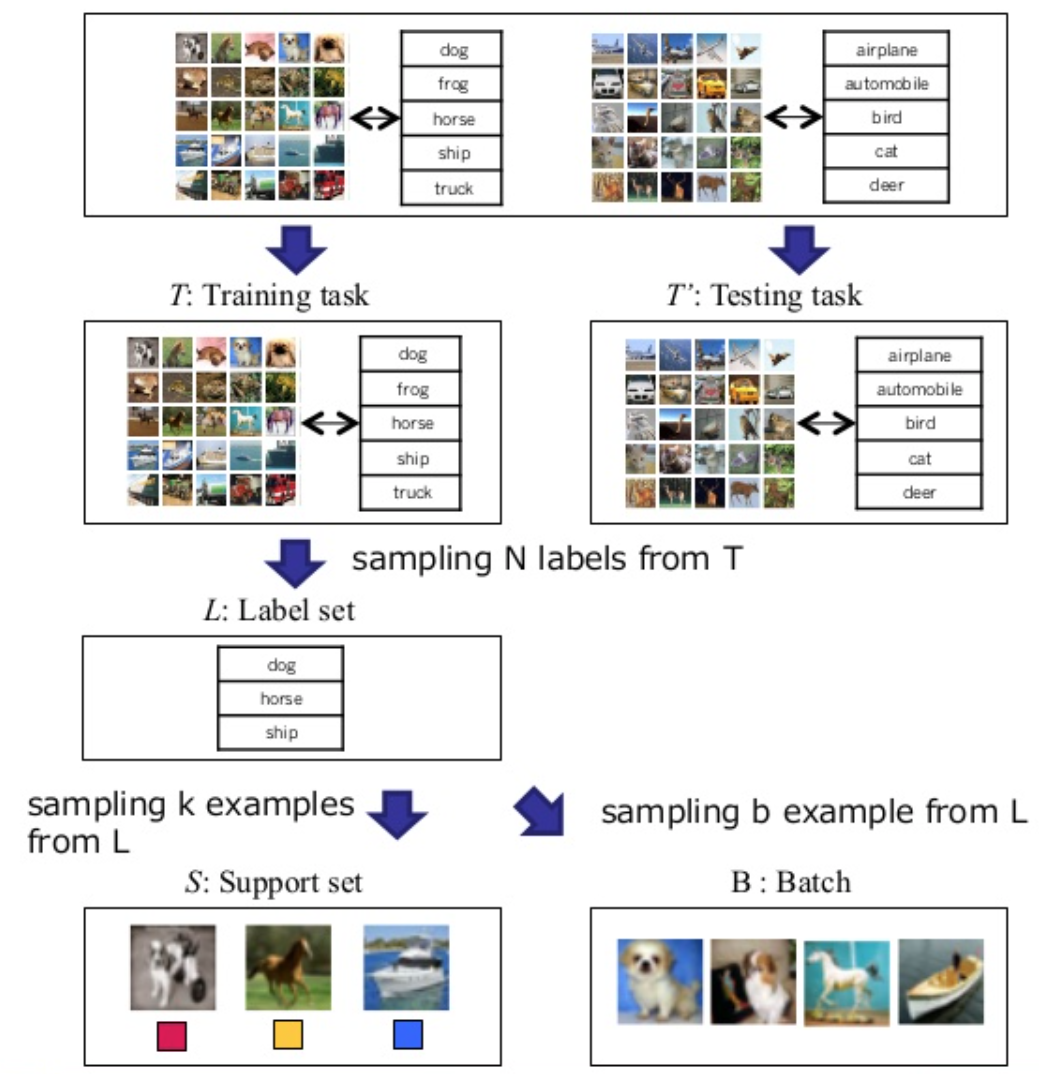
- Training 진행!!! \(\theta\) 훈련
- Support set \(S\)과 새로운 (테스트에 사용할) support set \(S’\)을 구성한다.
- 새로 구성한 support set, \(S’\)으로 \(\hat{y}\)를 만든다.
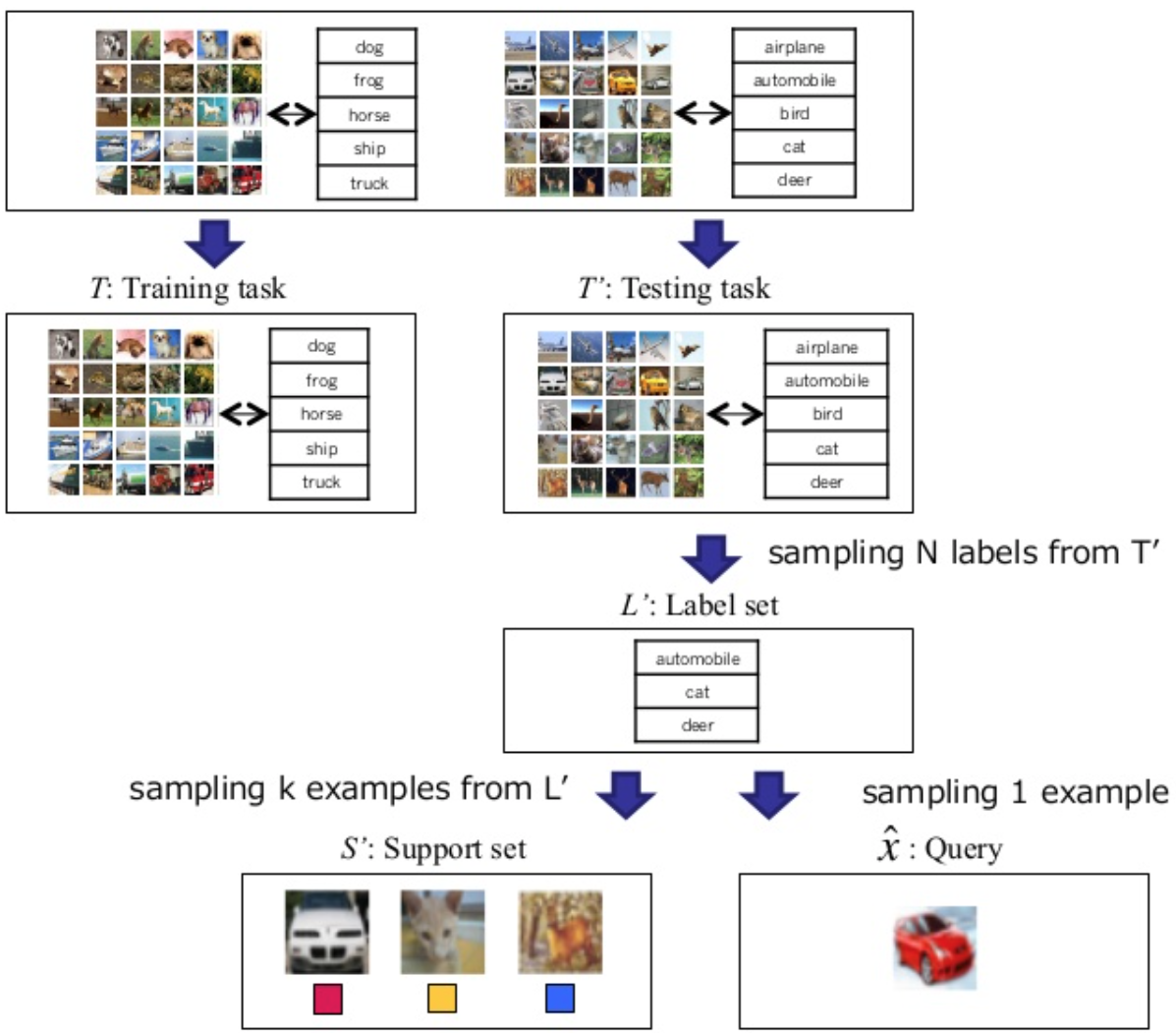
- \(\hat{y}\)으로 정답과 비교한다.
- 끝
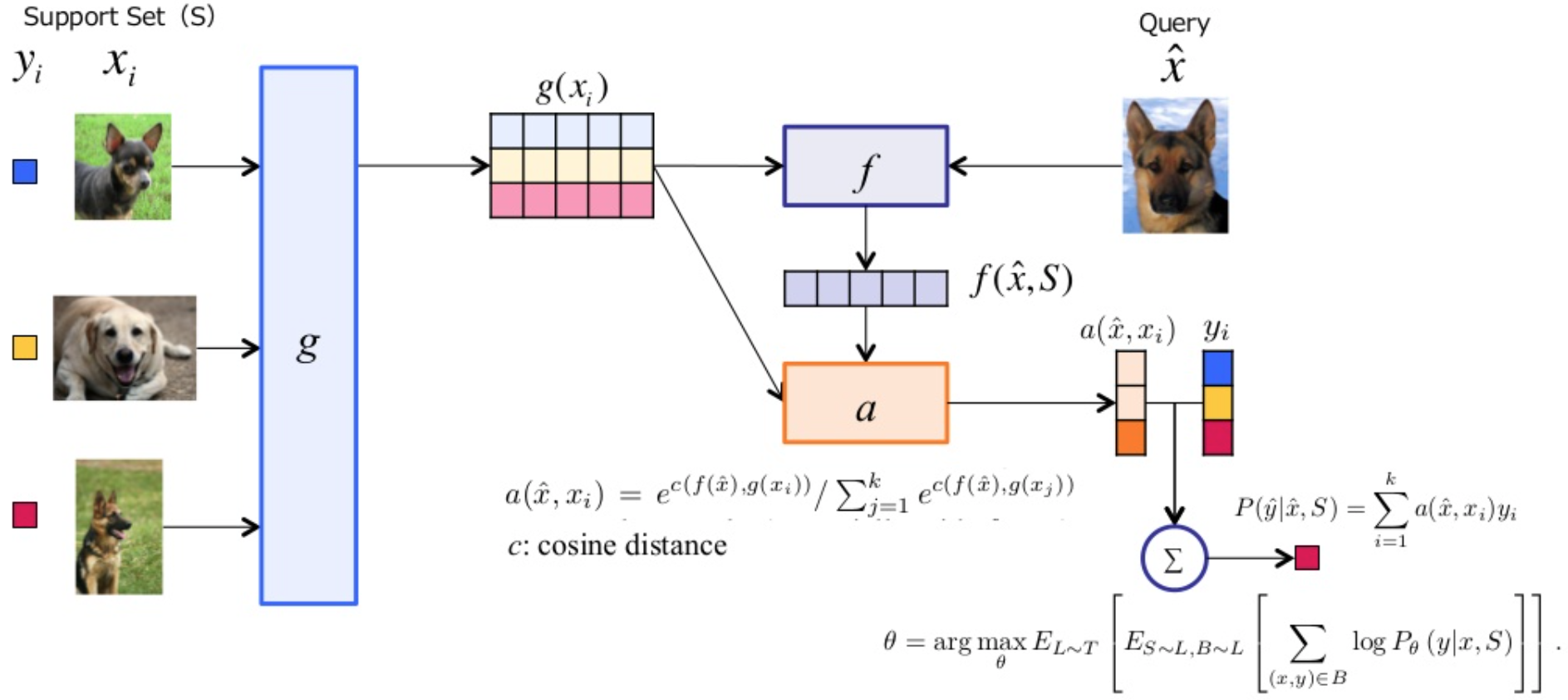
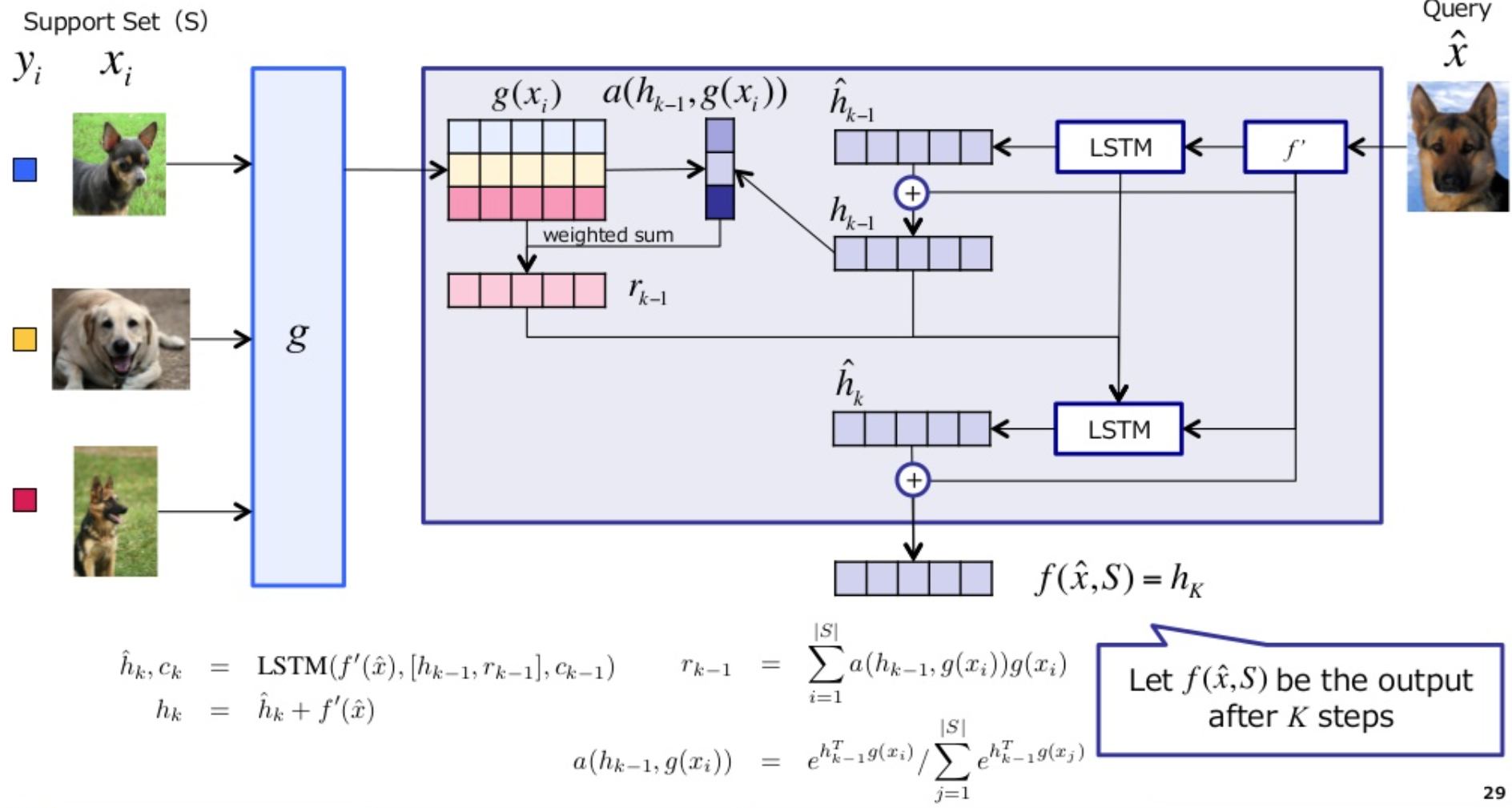
Model architecture
메모리에 저장하는 것과 유사하게 \(S\)에서 만든 정보를 이용하여 one shot learning에 활용
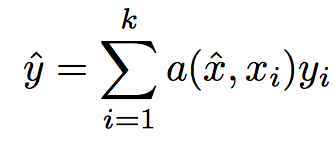
여기서 \(a()\)는 attention kernel임. 정의는
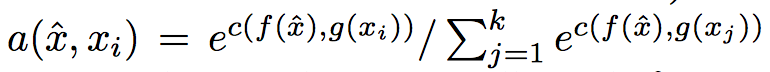
softmax + cosine similarity + feature extractor 정도로 표현 가능
\(\hat{y}\)가 나오고 나면, 그 다음부터는 label과 맞춰보면 끝.
여기까지만 보면 neural network하고 연관성은 전혀 없다.
Full Context Embeddings
appendix에서는 fully conditional embedding이라는 이름으로 -_- 나옴
$$f(x)$$와 $$g(x)$$를 neural network으로 구성해보자!
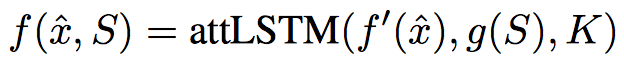 LSTM을 포함한 특이 구조
LSTM을 포함한 특이 구조
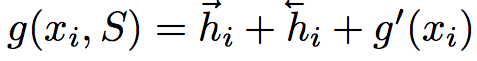 BLSTM + skip connection구조임
BLSTM + skip connection구조임
여기서 \(f’(x)\)와 \(g’(x)\)는 입력에 따른 1차 feature extractor라고 보면 된다.
이미지의 경우 CNN에서 softmax만 뺀 상태에서 벡터열을 가지고 옴
In detail
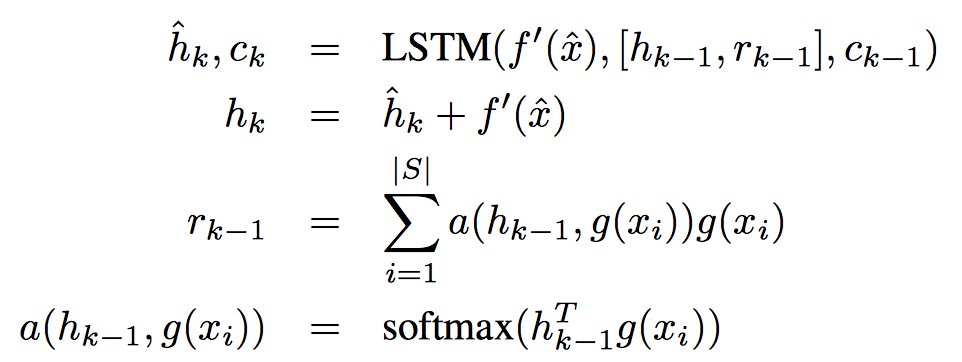
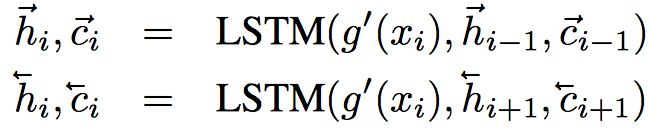
Training Strategy
Objective function은 다음과 같이 구성함
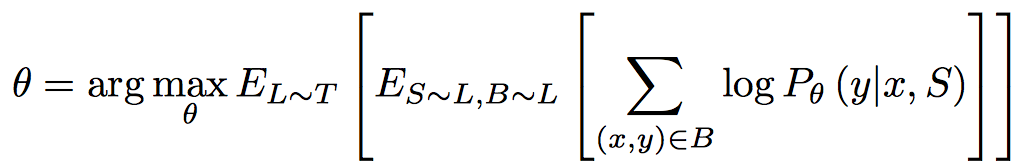 \(P_{\theta}()\)는 기존의 classification을 구하는 방식과 동일하다고 보면 됨
\(P_{\theta}()\)는 기존의 classification을 구하는 방식과 동일하다고 보면 됨
FCE in Image
FCE \(g\)
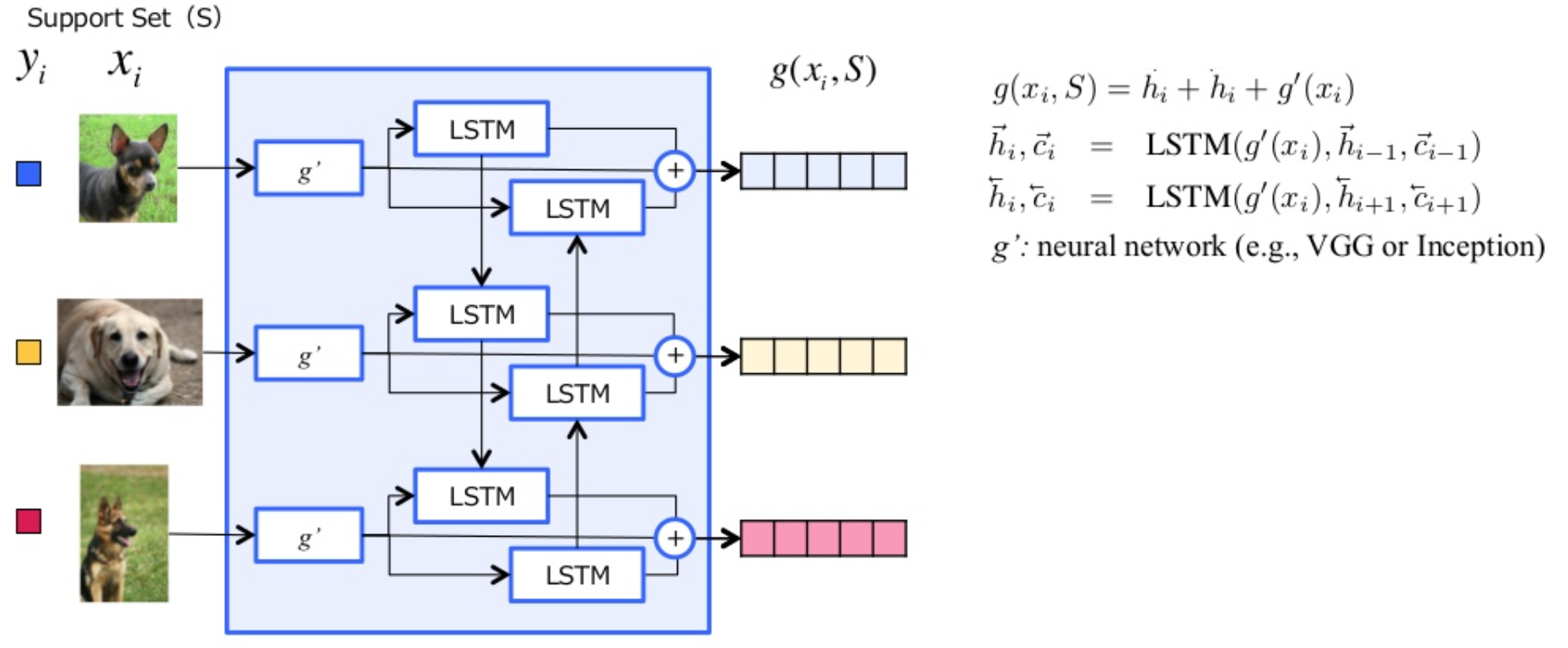
FCE \(f\)
Experiments
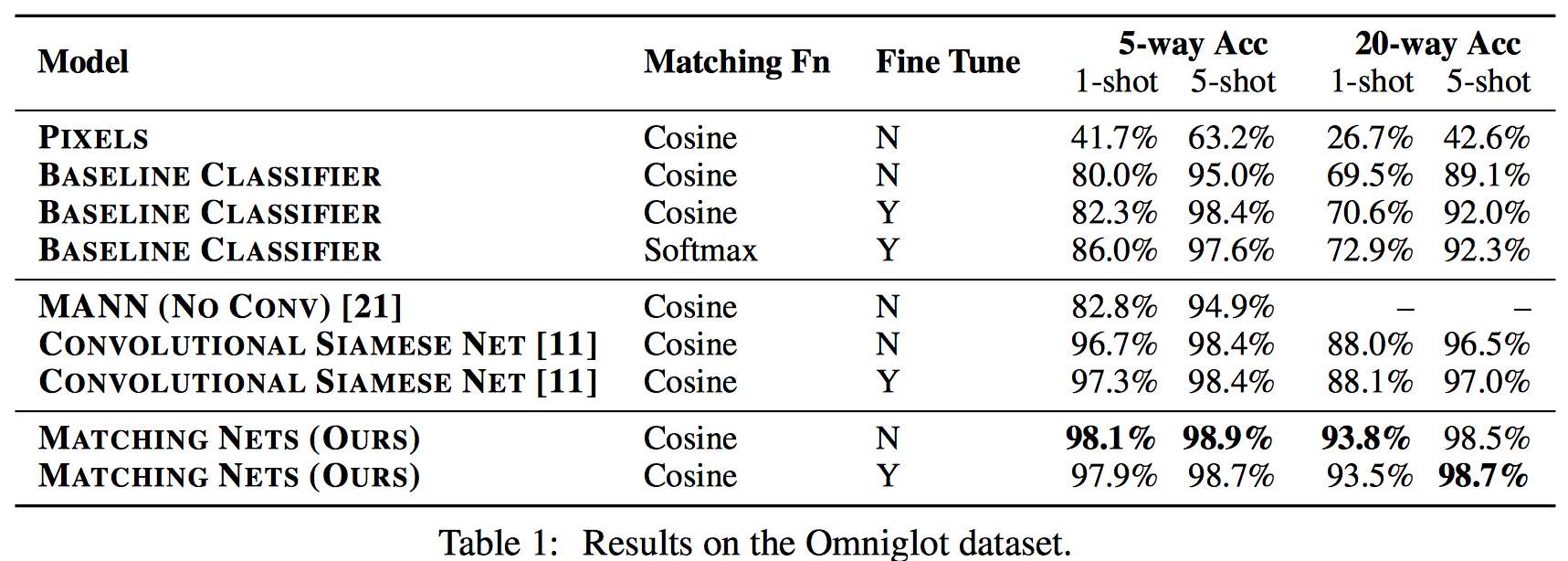
Omniglot

1623개 문자 (각 20개씩..)
one shot learning에 적합한 Database
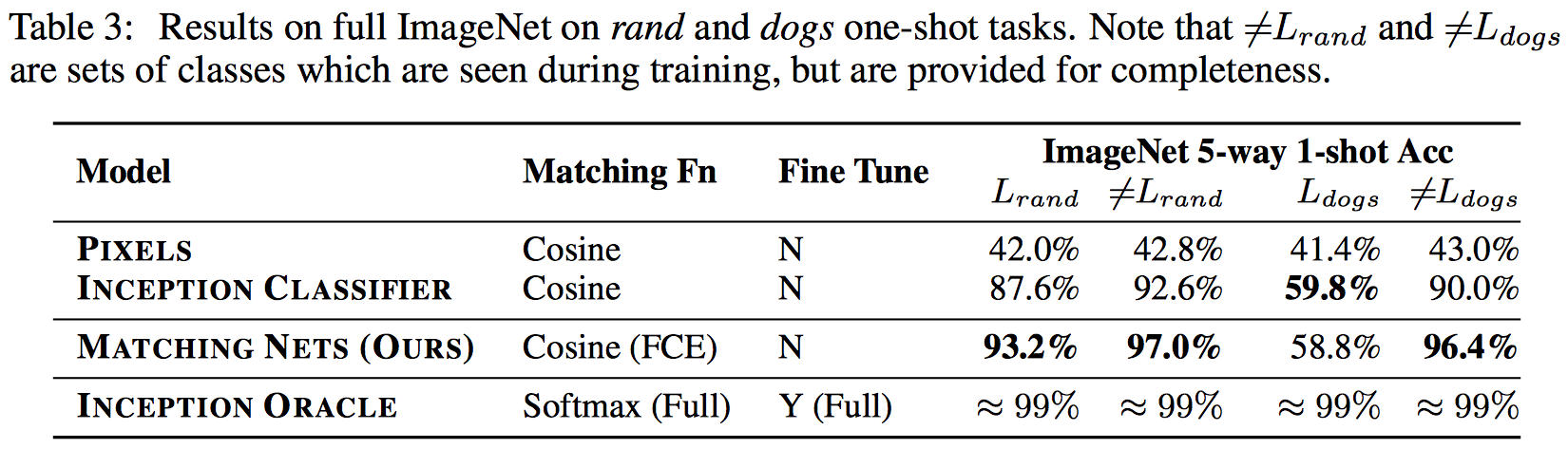
ImageNet
전체를 다쓰진 않고 random으로 118를 지운 것을 training으로 쓰고 118개를 테스트로
-> randImageNet
dogs만 지우고 (118) traing, dogs는 테스트로만
-> dogsImageNet
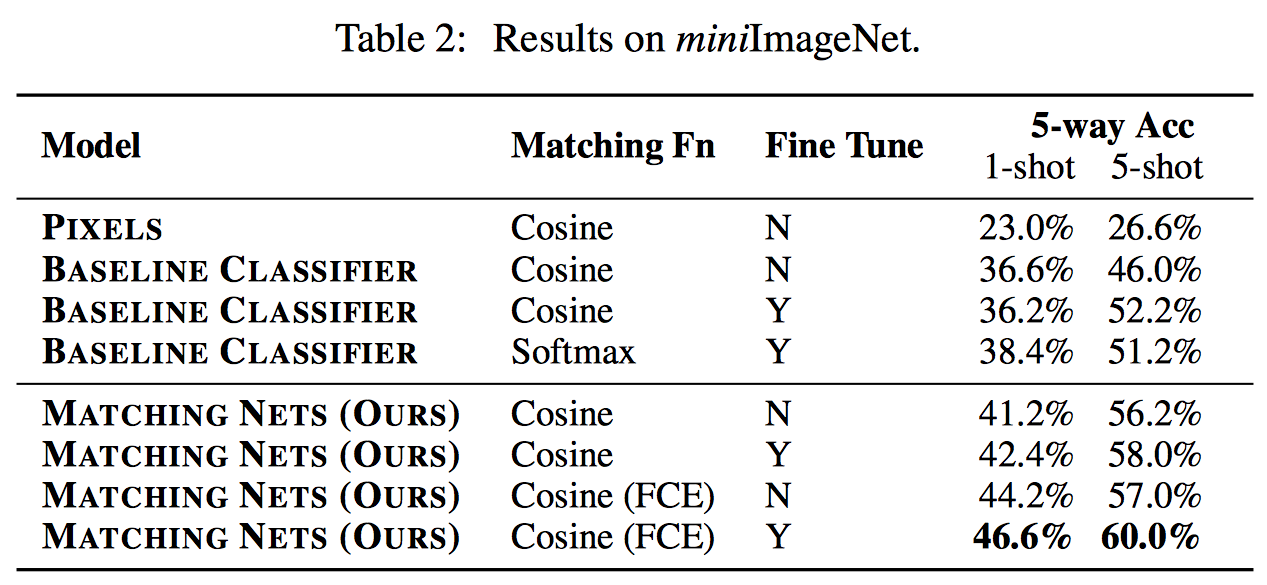
자체적으로 사이즈 줄이고 100개 클래스만 모아서 쓴거 (train/test=80/20)
-> miniImageNet

Conclusion
end-to-end one shot learning
Differentiable nearest neighbor
장점으로는..
성능도 일반 classifier를 쓰는 것보다는 더 향상됨
빠르게 학습 가능함
단점으로는..
클래스가 많아지면 느려짐..
kapathy’s blog에 언급처럼 비교대상에 대한 확인이 필요함
FCE 적용시 더 나빠지는 경우도 있음 (Omniglot)
hyper-parameter 로 되어 있는 tstep에 따라서 성능이 차이남(예상)
References
1606.04080 Matching Networks for One Shot Learning
Matching networks for one shot learning
paper-notes/matching_networks.md at master · karpathy/paper-notes · GitHub
GitHub - zergylord/oneshot