Phased_LSTM
Accelerating Recurrent Network Training for Long or Event-based Sequences
부제만 잘 읽어도 이게 뭘하려는 것인지 알 수 있음.
Accelerating Recurrent Network Training for Long or Event-based (aka async) Sequences
기본 LSTM 구조도
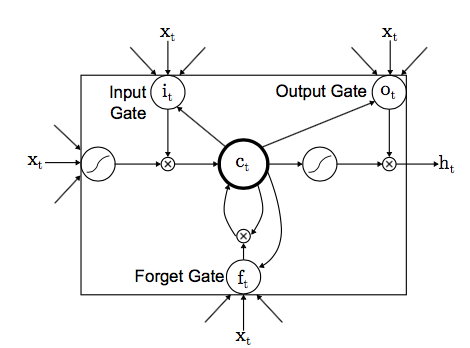
이게 일반 LSTM에 대한 구조도.
기본 LSTM 내용은 기존에 많이 다뤄졌을테니 그림 정도 소개로 넘어간다.
Phased LSTM 구조도
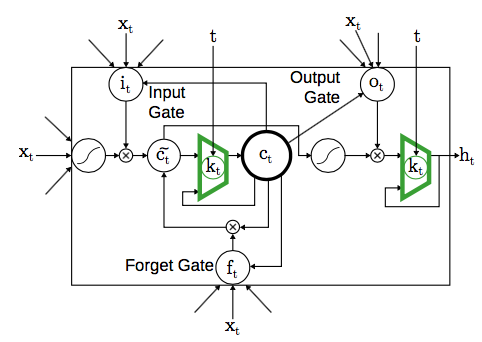
요게 Phased LSTM에 대한 구조도 그림만으로 이해해보자면,
- \(t\)라는 것이 입력으로 들어가고,
- 그것이 \(k_t\)를 결정하고,
- 이에 따라서 memory와 hidden에 대한 값이 영향을 받는다.
- 기타 path가 바뀌는 부분이 있는데 이 차이는 minor
기본 LSTM 수식
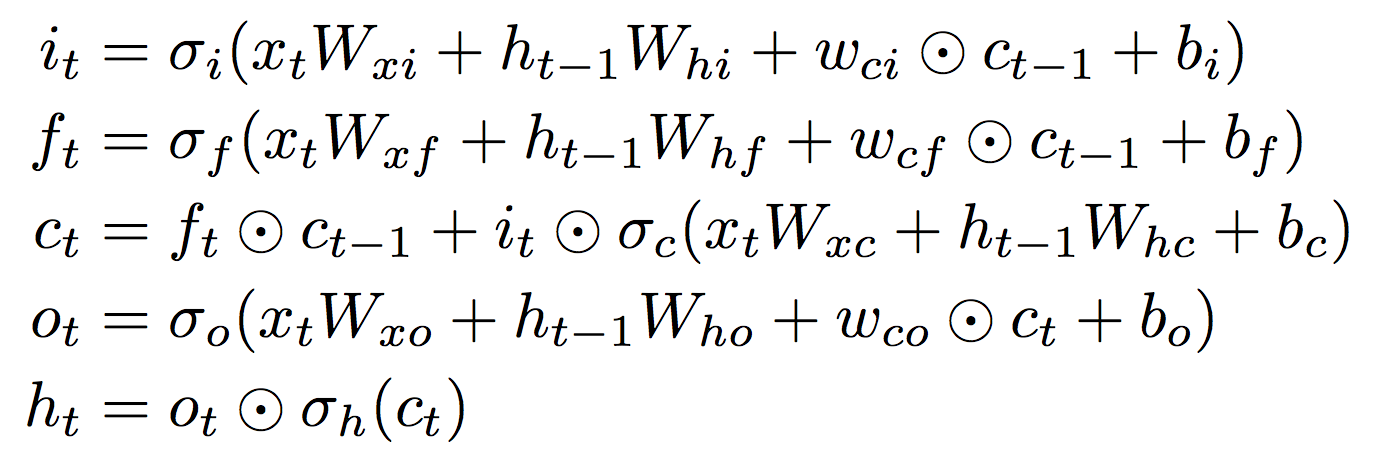
기본적인 LSTM에 대한 수식이다. 우선, 다 안다고 가정하고..
이 수식이 다음과 같이 변하면서 추가된다.
자세한 내용은 뒤에서 더 언급하고,
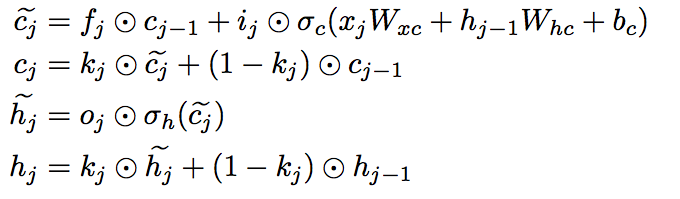
기본 LSTM와 Phased LSTM의 차이점
여기에 Phased LSTM은 time gate라고 하는 것을 추가한다는 것이다.
위에 그림에서 추가된 성분이 time gate라고 보면 되겠다.
time gate를 구성하는 3가지 요소- \(\tau\): real-time period
- \(r_{on}\): duration ratio of open phase
- \(s\): phase shift
특징은 이 3가지 파라미터 모두가 훈련 과정에서 학습된다는 점!!
이 내용을 그림으로 표현하면,
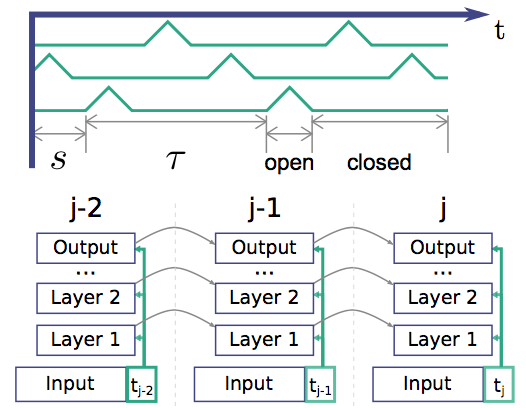
이렇게 보면 되겠다.
위에 green line이 실제 \(k_t\)에 대한 값이라고 보면 된다.
들어오는 \(t\)에 의해 계산되는 \(k_t\)의 값은
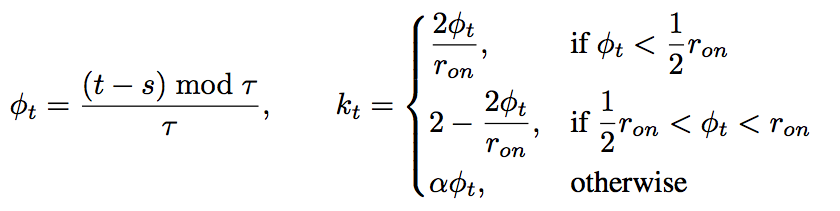
라고 보면 된다.
조금 복잡해 보일 수 있지만, 찬찬히 뜯어보면 위에 green line을 그대로 수식화 한 것으라고 볼 수 있다. 그림하고 비교할 때, close phase가 leaky 처리한다는 점과, open phase의 최대값이 1인 것을 염두하고 보면 쉽게 이해할 수 있다.
Phased LSTM 수식
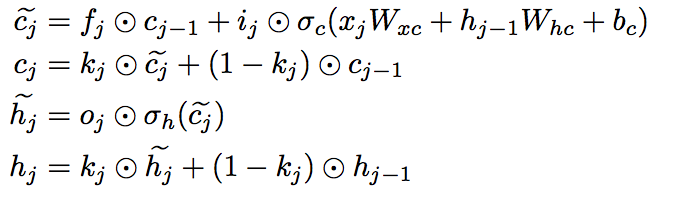
뭔가 수식이 더 단순에 보이는데, 메모리와 hidden에 대한 변경사항만 추가한 것이다. input, output, forget은 기존 LSTM과 동일하게 사용한다.
Phased LSTM 구조도에서는 \(\tilde{h_j}\)에 대한 표현이 없는데, time gate에 들어가기 전에 신호를 \(\tilde{h_j}\)라고 보면 된다.
보면 수식에서 조금 차이점이 time gate를 빼더라도 \(\tilde{h_j}\) 성분을 만드는데 \(\tilde{c_j}\)를 사용한다는 점이 있는데, 이 부분은 실제로 time gate가 hidden 앞에서도 동작을 하기 때문에 동작에 영향을 거의..주지 않을 듯..
그리고 \(c_j\)를, 즉, 메모리를 업데이트하는 측면에서 업데이트 하지 않는다면 기존의 메모리 값이 거의 사용됨을 알 수 있다.
Phased LSTM 동작 그림
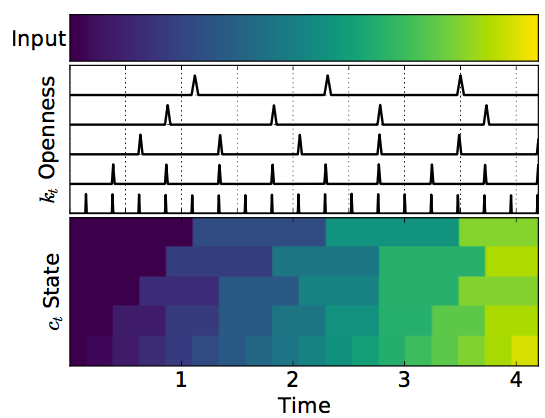
입력은 같은 상태에서 time gate 차이가 발생함에 따라 내부 메모리가 어떤 값을 가지게 되는지를 나타낸 것이다. 맨 위에 입력 하나에 \(k_t\) 하나, \(c_t\) 하나를 묶어서 pair로 해석하면 된다.
보면 이해할 수 있겠지만, \(\tau\)만 변화를 주고, \(s\)와 \(r_{on}\)은 고정을 해놓은 경우라고 볼 수 있다. 그에 따라 실제로 gate가 열릴 때만 \(c_t\)가 학습되는 거라고 볼 수 있겠다. 뭐 그렇게 만들었으니 당연하겠지만;;
기존 LSTM과 phased LSTM의 차이가 발생하는 부분
실제로 기존 LSTM와 비교해보자. forget gate가 0이 아닌 값을 가지게 되면, 추가적으로 의미있는 정보가 장시간 들어오지 않더라도 결국 메모리 decay는 일어나게 된다. (아니면 무지무지 작은 값으로 memory decay가 학습되던가..)
이에 반해서 phased LSTM은 open 구간에서만 decay가 일어나기 때문에 이 논문 제목에서 나온 training for long sequences에 적합하다고 볼 수 있겠다.
이에 대한 간략한 실험은 뒤에서 소개된다.
실험을 설명하기에 앞서,
- Theano, Lasagne를 이용해서 구현하였고
- adam을 optimizer로 이용했다.
- Close 구간에서는 훈련할 때는 \alpha를 0.001로 하고 test에서는 0으로 설정하였다.
- \(s\) (phase shift)는 [0, \(\tau\)]에서 균등하게설정하였고,
- \(r_{on}\)은 0.05로 고정해서 사용했다. (첫번째 task에서만..)
Task 1: Frequency Discrimination Task
뭔가 대단해보이는 task 이름 같지만, 결국 sine wave를 입력으로 넣을 건데 이 중에 freq.가 일정 범위에 있는지 아닌지를 판별하는, on/off (two classes)문제라고 보면 되겠다.
학습할 때는 구분 freq. 내에서 균등하게, 구분 freq. 외에서 균등하게 샘플을 만들어서 훈련한다.
다음 대상에 대해 비교를 하는데,
- 기본 LSTM
- batch-normalization (BN) LSTM
- Phased LSTM
phased LSTM은 \(t\) 정보를 추가로 가지고 가는 꼴이 되니까,
공평하게(?) 나머지 두 LSTM 구조에도 입력을 넣을 수 있도록 한다.
그래서 Phased LSTM은 1-110-2의 구조를 갖되 \(t\)가 별도로 들어가고,
나머지 둘은 \(t\)를 포함하니까 2-110-2의 구조를 가진다.
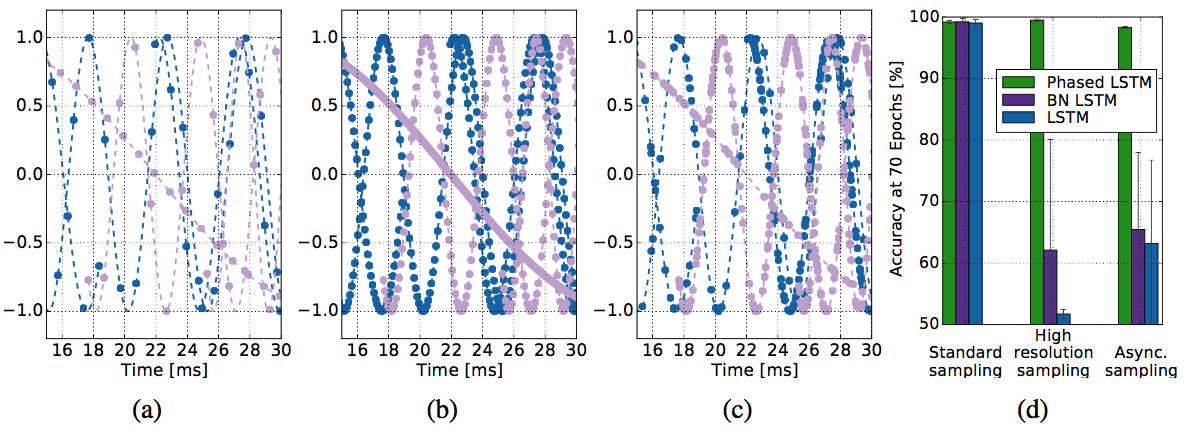
비교 대상은 3개고,
비교할 데이터도 3종류다.
sine wave가 존재할 때,
- 1ms 마다 sampling을 할 경우 (standard sampling)
- 0.1 ms 마다 sampling을 할 경우 (oversampling, high resolution)
- 1ms 마다 한 경우와 동일한 수를 sampling하되 sampling 구간은 무작위로 (async sampling)
결과를 보면 분류하는 성능이 제안한 Phased LSTM이 월등하게 좋을 것으로 나타난다.
뭐 그런줄 알았는데!!
사실은 최종 성능이 월등하게 좋아진다는 것은 아니고 70 epoch에서 저렇게 차이가 난다는 것이고, 오래오래 돌리다보면 high resolution의 경우 base line (standard sampling) 정도 수준으로 올라오긴 한다.
그래도 async에서는 자신들이 월등하다고 함.
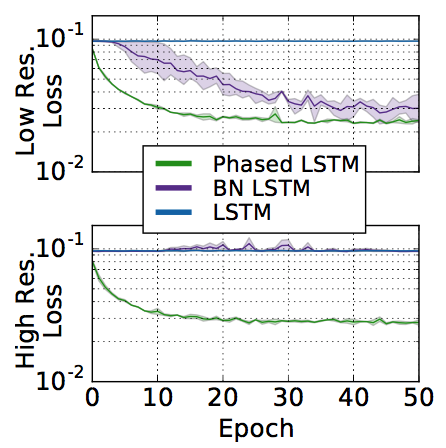
실제로 이 task를 하나의 sine wave가 아니라 2개의 sine wave로 바꾸어 연산하더라도, phased LSTM의 경우 빠르게 converge되는 것을 볼 수 있다. 그 learning curve는
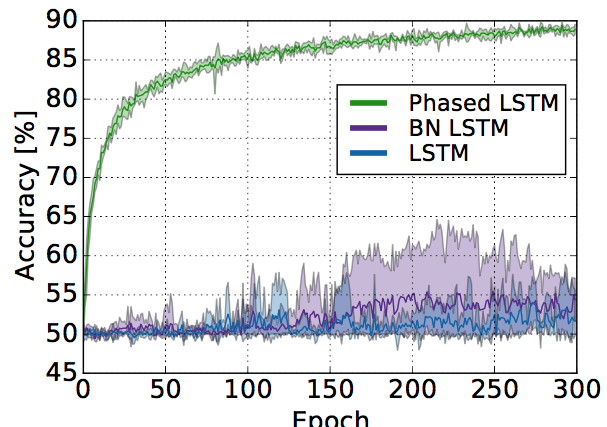
bold line은 여러번 테스트한 것의 mean값을 나타내고, transparency로 표현한 area는 여러번 테스트 했을 때 나오는 variance 구간이다.
실제로 variance도 적은 것을 확인할 수 있다. 이것도 큰 장점인듯
Task 2: Adding Task
이 task에 대한 자세한 설명은 [16]을 참고하면 된다.
S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.

정리하면, 입력이 2차원 벡터다. 1차에는 [-1, 1] 실수가, 2차에는 1, 0, -1이 들어있다. 이 중에서 1인 숫자들만 더한 결과를 뽑는 것이 목표이다.
T를 설정하면 첫번째와 T/2-1 번째 성분만 2차에 1을 설정하고 나머지는 0 대신에 T/2와 맨 마지막 성분에는 -1를 설정한다.
이럴 때 실제로 2차에 1로 설정된 결과의 합만 잘 구하는지 보는 것
결국 두 수를 더하기 할 텐데, long time-lag라도 잘되는지 보는 것이다.
-1은 노이즈처럼 사용하는 것으로 보이고, 실제로 0.04 이하로 에러가 나면 맞는 것으로 가정한다.
칠판에 그리면 이해가 편할 듯!
암튼 이거 같은 경우에는 longer period에서 time gate를 사용하는 phased LSTM이 효과적으로 학습함을 보인다는 것을 확인하는 task다.
입력 길이를 500으로 했을 때, 기존 LSTM과 비교해서 성능이 좋아지는 것을 확인할 수 있다.
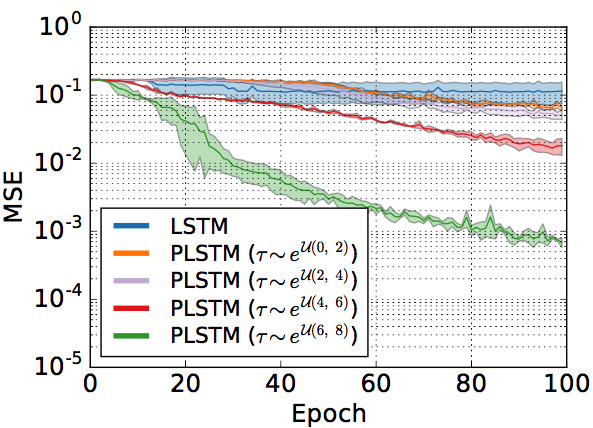
\(\tau\)에 대한 설명이 추가로 들어가야하는데 아직 이해를 못하겠 ㅠ.ㅠ
np.exp(6)은 403 np.exp(8)은 2980인데, T가 500인 경우니까 이 경우가 제일 잘 되는듯,
사실 두 수에 간격은 절반인 250이 되는데, \(\tau\)가 250 이상이라고 하더라도 두 수가 각각 다른 unit cell에 저장된다고 보면 250 이상이더라도 동작하는데 문제는 없을 것 같음.
Task 3: N-MNIST Event-Based Visual Recognition
N-MNIST에 대한 정보부터 찾아보자;;;
G. Orchard, A. Jayawant, G. Cohen, and N. Thakor. Converting static image datasets to spiking neuromor- phic datasets using saccades. arXiv: 1507.07629, 2015
https://arxiv.org/abs/1507.07629
아아,, 이건 내가 할 수 있는 범위가 아니다.
동영상을 봐도 모하겠다는 것인지 모르겠고 알고 싶지도 않다;
Converting Static Images to Neuromorphic Datasets - YouTube
Neuromorphic Caltech101 data - YouTube
Task 4: Visual-Auditory Sensor Fusion for Lip Reading
음성하고 영상을 동시에 이용하여 음성 인식하는 방식임. GRID라는 DB를 이용하는데, 30명에 대해서 1,000 문장을 발화하고 정해진 51가지 단어를 이야기한다. 이때 영상과 음성을 저장해놓은 것 특징이라고 하면 두 입력(a/v)가 주기가 다르다는 것
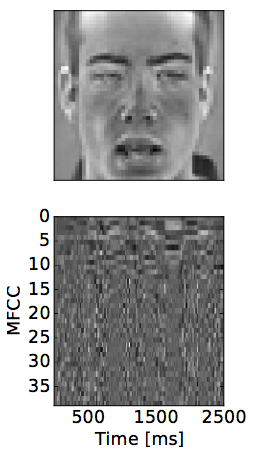
전처리로 openCV를 이용해서 grayscale 48*48 얼굴만 가지고 온다.
사실 단어셋이 제한적이라서 음성만 해도 99%가 나온다.
근데 잡음이 끼거나 이럴 때도 잘 되게끔 하려고 하는 방식이라고 이해하면 되겠다.
영상은 3*(conv + pool)을 거쳐서 16*2*2 이 되도록 만들고 이를 입력으로 사용한다.
음성은 39차 MFCC를 만들고 (13에, delta, delta-delta) 샘플을 보면 다음과 같다.
Networks
영상은 결국 64-110
음성은 결국 39-150로 만든다.
이 둘을 merge-1에서 250으로 묶고
하나의 layer를 더 쌓고 (250)
그 다음에 softmax (51)
그림으로 표현하면
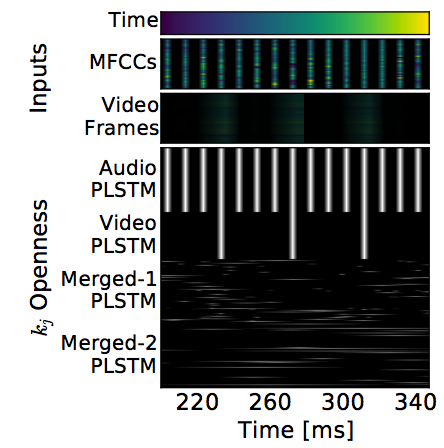
오디오랑 비디오가 사실 frame이 맞지 않는다. 비디오는 25 ftp고 오디오는 10 ms 단위로 MFCC를 뽑으니까.. 이런 측면에서는 phased LSTM이 효과적일 것 같긴하다.
\(\tau\) 하고 \(s\)는 audio/video PLSTM에 대해서 고정해놓고 사용한다. 나머지에 대해서는 훈련을 통해서 획득한다. 보면 알겠지만 \(k_t\)는 hidden unit만큼 존재한다.
실제로 훈련해서 결과를 뽑아보면 98% 보다 상회하게 나온다. 일반적으로 fusion을 하는 순간 성능이 많이 떨어지는 것을 감안하면 꽤나 괜찮은 결과로 보인다.
비디오만 가지고 하는 video-only의 경우 결과가 잘 안나오긴하는데 이 경우에서도 Phased LSTM을 사용하면 빨리 떨어진다는 것이 특징이고 실질적으로 81.15% 정도 나왔는데 이정도면 state-of-the-art에 근접한 것이라고 함. 결과 그림은 다음과 같다.
정리
\(t\) 정보를 활용할 수 있는 Phased LSTM를 제안했다.
- 장점으로는
- 빠르게 converge
- Async. 조건에서도 성능이 잘나오고,
- frame sync가 안맞는 이종 데이터를 엮어서 처리할 때, 적절한 방식이고
- GRU 로 확장도 편함.
- 아직 이해가 잘 안되는 부분은
- Task별 어떨 때는 뭘 고정해놓고 쓰는데 그래도 되는지;;
- 그냥 다 풀고 해도 실제로 되는지?
- 실제 \(\tau\), \(s\), \(r_{on}\)은 어떻게 학습될지?