논문은 1705.08690 Continual Learning with Deep Generative Replay를 참고하면 된다.
T-brain에서 낸 논문 @.@
부럽다.
Sequential Learning
개인적으로는 처음 접한 컨셉이긴 한데, sequential learning은 하나의 task를 해결하기 위한 다양한 sub-task를 배우는 과정이다.
반드시 sub-task일 필요는 없을 것 같긴하다만, 원래 취지는 그러하지 않을까 싶다.
Continual Learning
이를 위해서 task별로 훈련을 연속적으로 하다보면 뭔가 되지 않을까?
문제는 하나의 모델에 다른 내용을 넣다보면 catastrophic forgetting 이라는 것이 발생한다는 것이다.
즉, 하나의 모델에 다른 task를 훈련하기 시작하면 기존의 task에 대한 정보는 다 까먹게 된다는 말씀.
그래서 이걸 좀.. 어떻게 해결하고 싶다는 것이다.
Deep Generative Replay
여기서는 generative model을 이용해보자는 것이다.
조금 더 근본적으로 보면,
task1, task2, task3 이런식으로 훈련할 때, 최종적으로는 1,2,3 모두의 database를 다 모아서 훈련하면 괜찮게 나오더라는 것.
다만 여기서는 database를 다 모아서 매번 키워가며 학습하기 어려우니(?) 또는 실제 서비스에 접목하는 입장에서 database 배포가 어려운 점들이 있으니, 직접 database를 이용하지 말고 generative model을 통해서 간접 databse를 만들어서 학습에 사용하자는 것이다.
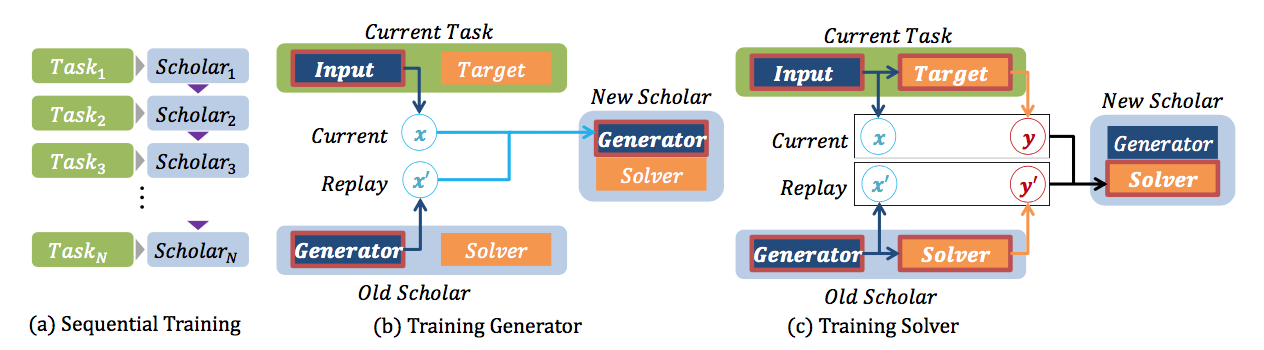
그림을 설명해보면, generator와 solver가 pair로 구성되는데, generator는 GAN의 G,D를 다 가지고 있다고 보면 되겠고, solver는 우리가 일반적으로 classification으로 사용하는 모델 정도로 보면 되겠다.
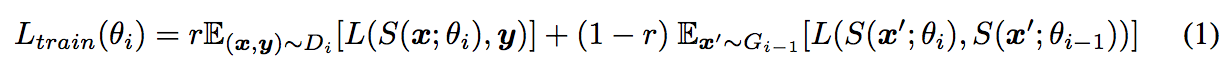
수식을 보면 \(r\)은 실제 database 대 generated sample의 비율에 의해서 결정된다.
Experimental result
우선은 거의 유사한 task지만 database가 다른 MNIST 숫자와 SVHN을 가지고 continual learning을 했다.
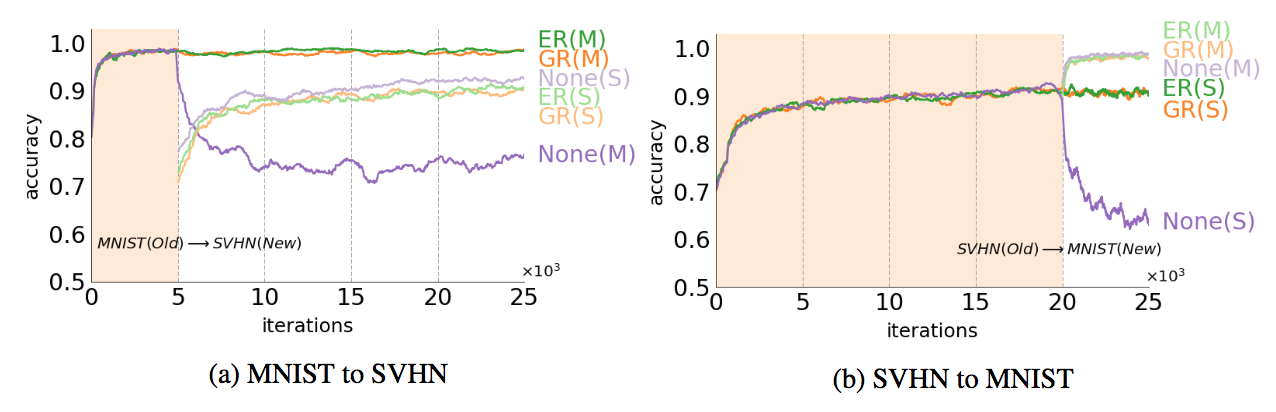
ER의 경우 generative model을 사용한 것이 아니라 직접 datasbase를 사용한 것이고 (upper bound) GR이 replay를 사용한 것이다.
비교를 해보면 task change가 일어난 이후에도 각각에 대한 분류가 여전히 잘되고 있는 것을 확인할 수 있다.
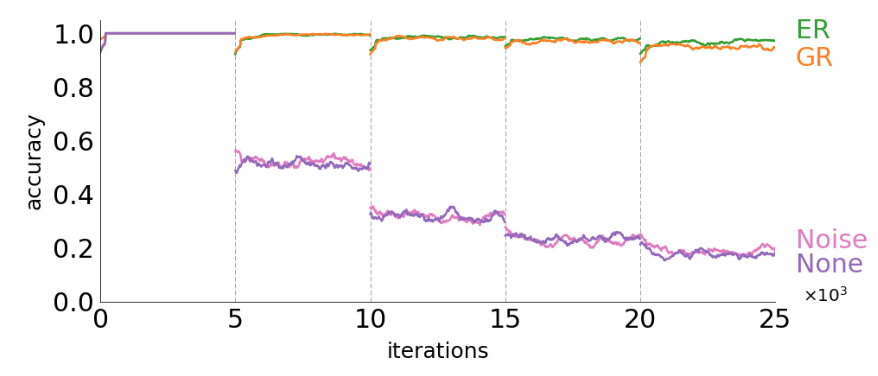
MNIST에서 2개씩 모아서 다른 task로 정의하고 continual learning을 걸더라도 replay를 사용하지 않은 것과 비교하면 효과를 쉽게 볼 수 있겠다.
정리
요약하고 요약하면 아래 문장 정도로 묶을 수 있을 것 같다.
DB 대신 Generative model을 이용하여 continual learning을 하더라도 잘 된다!!
물론 그 외에 실험적 내용이라든지 기존에 제안됐던 내용들에 대한 review 등도 눈여겨 볼만하다.
그리고 결과에 대한 해석도 상세히 서술하고 있다.
처음에는 이 논문 다른 분이 정리해주신 것을 듣고도 개인적으로 잘못 생각해서 엉뚱한 그림을 그리고 있었는데 저자분께 문의하니 친절히 매우 빨리 답장을 주셔서 이해하는데 큰 도움이 됐다. 자세히 못읽고 물어봐서 죄송하긴 했지만 ㅠ.ㅠ