Keras - Masking layer
링크는 여기에…
Core Layers - Keras Documentation
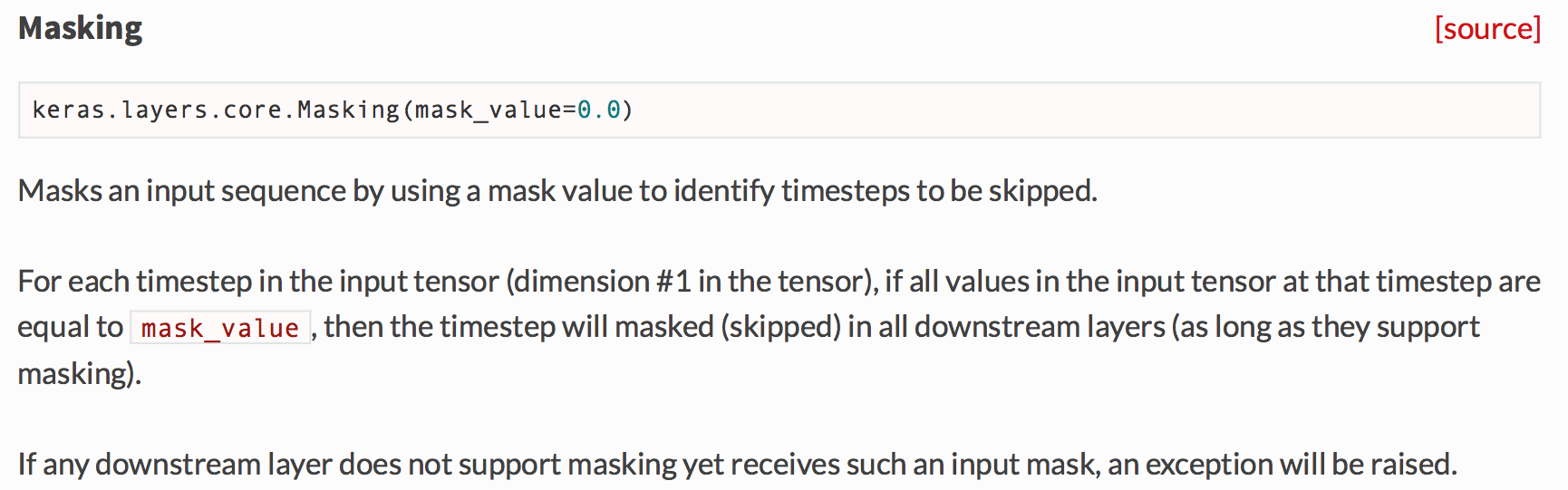
내용을 보면, timestep을 적용할 때 masking이 필요한 케이스에 대해서 처리하는 것이다.
사실 masking 내부를 보면 mask라는 정보를 서로 주고 받는데, 실질적으로 생성되지 않으면,
나중에 mask 있는 녀석과 없는 녀석을 합칠 때, mask 없는 녀석은 모두 필요한 정보로 표기하게 된다.
이거는 실제 값을 0이나 쓰레기 값을 넣어 놓더라도 발생하는 부분이다.
따라서 mask 정보를 추출하는 layer 가 필요한다. 이것이 바로 masking layer
일반적으로 text 처리를 할 경우 embedding layer에서 mask_zero=True를 통해서 mask 생성이 가능하니까 안해도 되는데, 음성이라든지, 영상을 음성이나 text에 맞춰서 처리를 한다 하면 이야기가 달라진다.
음성이나 영상에도 mask 정보를 심어줘야 하니까 말이다.
일반적으로는 multi-modal이나 image captioning, visual QA 정도로 섞어서 데이터 처리하는 것이 아니라면 필요가 없지 않을까 싶긴하다.
그럼에도 알아두면 유용한 layer!!
예제 코드는 다음과 같다.
model = Sequential()
model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
model.add(LSTM(32))
input_shape이나 sequential()의 최상단 layer 기 때문에 붙는 것이라고 보면 되고, 다른 처리 할 것 없이,
mask_value에 설정된 값을 따라서 mask를 생성한다.
다만 주의가 필요한 부분은 image feature를 이용할 경우, relu() 를 사용하면서 일부 값들이 0으로 나올 수 있기 때문에 이런 경우에는 0보다 -1로 데이터를 만들어 주는 것이 더 적당하겠다.
즉, 컨텐츠에서 나올일이 없을만한 수치로 mask_value를 설정해주면 좋을 것이라는 이야기.
뭐,, 사실 내용을 보면 일부가 0인 time step의 경우 mask 처리를 안할 수 있지만, 그래도 운 나쁘게 모두 0이 나올 수도 있으니까;;;
한걸음 더 들어가 보겠습니다.
본 김에 코드까지 보자. 링크는
https://github.com/fchollet/keras/blob/master/keras/layers/core.py
실제로 보면
def call(self, x, mask=None):
boolean_mask = K.any(K.not_equal(x, self.mask_value),
axis=-1, keepdims=True)
return x * K.cast(boolean_mask, K.floatx())
맨 뒷차원에 대해서 mask_value를 가지고 not_equal() 처리한다.
이러면 결과는 False/True로 나오게 된다.
이걸 K.any()가 0/1로 바꿔주고 그것을 mask로 사용한다.
그리고 compute_mask()에서는 여기까지만 정보를 가지고 return을 한다. 엄밀히는 dim을 줄여서..
call()의 경우에는 masked value를 반환해야하기 때문에 입력에 mask를 적용해서 return 한다.