Embedding layer
embedding layer는 실제로 text를 처리하는데 초기에 사용되는 layer다.
word2vec에 대한 결과를 받는 부분이라고 보면 되고,
그래서인지, 실제로 기존에 훈련된 weights도 그대로 넣고 사용할 수 있도록 method가 구성되어 있다.
이 포스트는 사실 embedding layer가 중심은 아니라서 간략히만 살펴보면,
입력으로 (batch, max_length)로 넣으면
출력으로 (batch, max_length, embedding vector size) 형태로 출력된다.
one-hot vector 로 바꾸는 과정은 내부적으로 처리가 된다.
보통 max_length에 해당하는 부분에는 word index가 들어간다고 보면 되겠다.
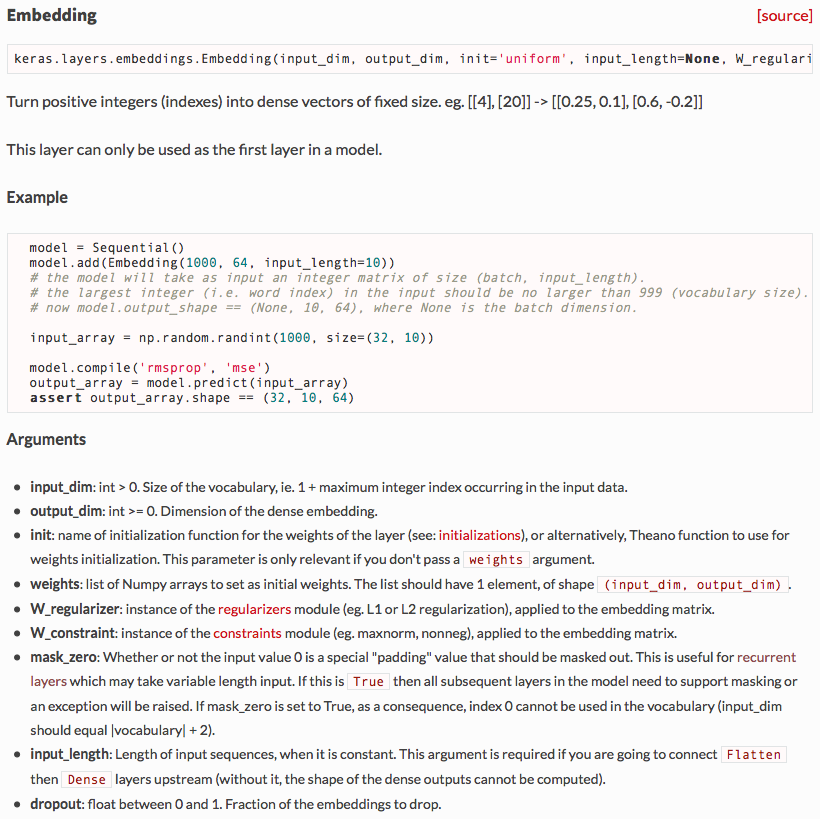
예시를 보면 다음과 같다.
model = Sequential()
model.add(Embedding(1000, 64, input_length=10))
# the model will take as input an integer matrix of size (batch, input_length).
# the largest integer (i.e. word index) in the input should be no larger than 999 (vocabulary size).
# now model.output_shape == (None, 10, 64), where None is the batch dimension.
input_array = np.random.randint(1000, size=(32, 10))
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64)
Mask
다만 옵션 중에 보면 mask라고 하는 부분이 있는데 이번 포스트에서는 이 내용에 대해서 설명한다.
tf나 th 를 사용했던 사람이라면 이미 알고 있을만한 기능이긴한데,
text나 audio와 같은 신호를 처리하면 항상 따라다니는 문제점이,
sample 별 길이가 다르다는 것이다.
문장별 판단을 한다고 하더라도
모든 문장의 길이가 같다고 볼 수 없다. (절대 그럴리 없겠지).
따라서 훈련을 할 때는 max_length를 설정한 다음에
그보다 짧은 성분에 대해서는 처리하지 않도록 masking 하는 작업이 필요한데,
이 부분을 처리하는 argument가 mask_zero라고 하는 flag이다.
default로는 False로 되어 있고, 실제로 mask가 필요한 경우에는 True로 설정하여 사용한다.
Mask 설정 이후 layer
설정을 하고 나면 항상 이 부분이 걱정인건데, 실제 mask 정보들을 어떻게 받아서 다음 layer에 넘기느냐 하는 부분이다.
다행(?) 인것은 keras에서 이 내용은 알아서 처리 해준다.
mask_zero를 True로 하면 내부적으로 mask 정보가 다음 layer로 전달되고
실제 훈련을 할 때도 loss에 이 정보를 활용해서 처리해주게 된다.
다만 설명을 보면 알 수 있다시피,

하위에 연결된 layer에서 mask 정보를 지원하지 않는다고 하면, 아예 exception을 발생시켜버린다.
아마 모델을 만드는 과정에서 바로 알 수 있거나 늦어도 compile 과정에서 에러가 발생할 것으로 본다.
recurrent layer (SimpleRNN, LSTM, GRU)는 물론이고 merge layer까지 mask를 지원하는 것을 알 수 있다.
물론 이 정보 보려면 문서나 code를 뒤져보면 알 수 있다.
다행히도(!) 이러한 정보는 wrapper 수준에서 볼 수 있도록 해 놓았기 때문에 큰 문제는 아닐 것으로 보인다.