Paper - End-to-End Memory Networks
링크는…
1503.08895 End-To-End Memory Networks
많이 회자되던 메모리 네트워크다.
벌써 나온지 2년이 지난 논문이지만,
아직 못본 것을 반성하면서 정리해본다.
뭐하는 녀석이냐?
Neural Turing machine과 비슷하다고 볼 수도 있겠다.
그래도 그림으로 보면 더욱 뭐하는지 쉽게 이해할 수 있겠다.

한 응용 예에 한하지만, 우선 필요한 부분이 딱 저거라서, 저기에만 맞춰서 설명을 해보려고 한다.
결국
입력으로 문장들이 주르륵 들어왔을 때, 그 내용을 기반으로 하여 질문을 받아 합당한 대답을 하는 것이다.
여기서 달라지는 것은
- 기존의 LSTM 등을 이용한 QA쪽에서는 context와 query가 입력으로 같이 들어가서 출력을 뽑는 것이었다면, 여기서는 다른 입력으로 들어가서 출력을 뽑아낸다.
- 메모리 뱅크(라고 표현해도 되려나?)를 내부적으로 가지고 있다는 점은 neural Turing machine과 비슷하지만, 집어오는 방식과
in_memory,out_memory가 나뉜다는 점이 다르다고 할 수 있겠다.
구조를 찾아보자.
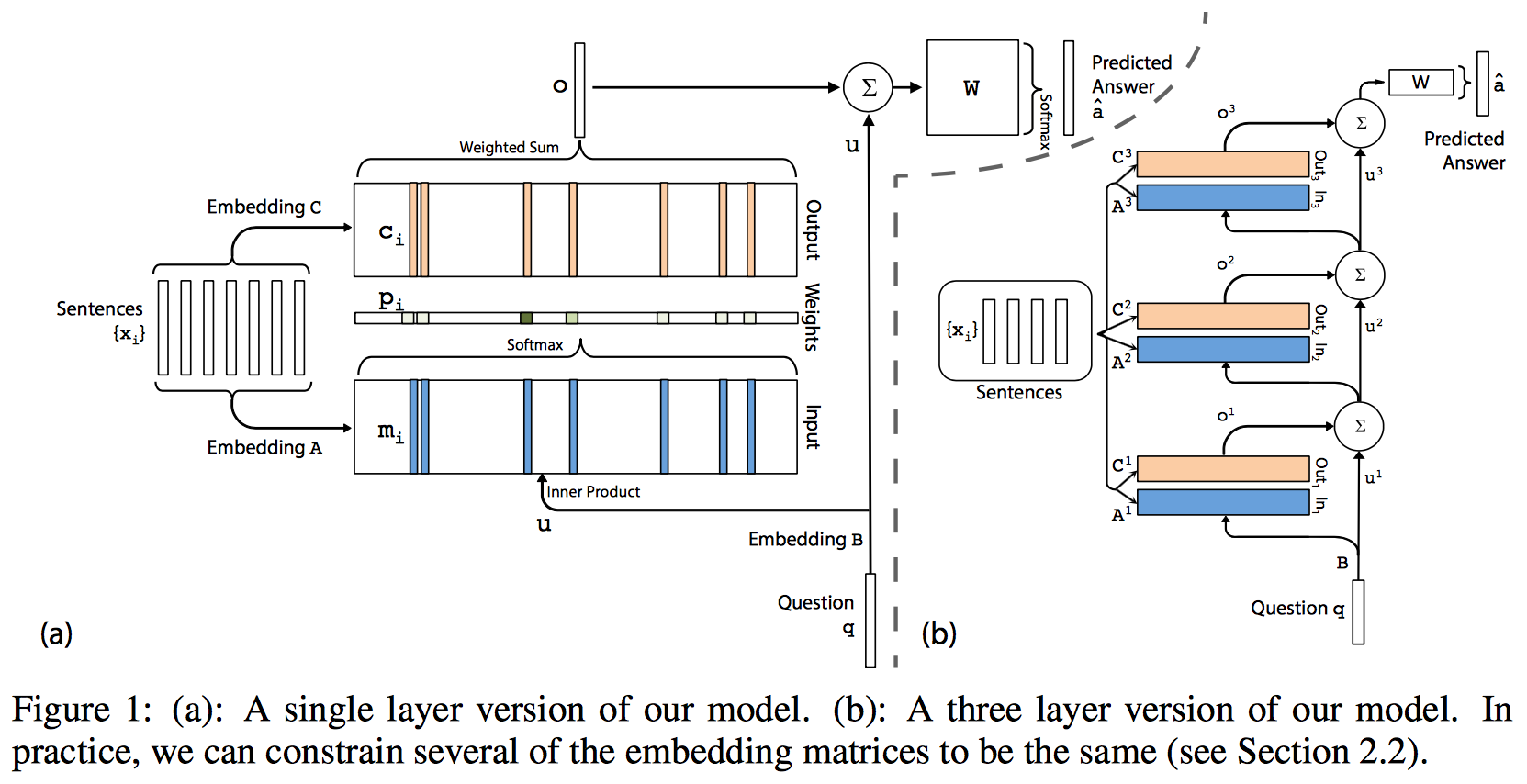
조금 복잡해 보일 수 있다.
하지만 우선 (a)만 이해하면 된다. 그리고 (b)는 stacking해 놓은 것이라고 보면 되겠다.
그림만 보고 간단하게 정리하면
근거 문장 (\(x_i\))는 질문이 들어오기 전에 두개의 메모리로 들어가는데,
각각 다른 embedding matrix를 통해서 들어간다.
\(m_i\)와 \(c_i\)를 구하는 방식은 뒤에서 BoW 방식이나 position encoding 방식이냐에 따라서 조금 달라지기 때문에 나중에 설명하도록 하고,
\(m_i\)와 \(c_i\)가 구해졌다고 쳤을 때, 먼저 메모리 출력을 구하는 방식은 다음 식과 같다.
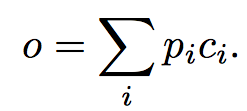
여기서 \(p_i\)는 입력 메모리와 query에 의해 계산되는 값이다.
마치 pointing하는 역할을 한다고 보면 될 듯하고, 구하는 방식은 다음과 같다.
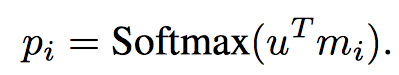
여기서 \(u^T\)는 query 문장이 embedding을 통해서 변환된 vector이다.
최종적으로는 다시 query와 메모리 출력을 이용하여 우리가 원하는 답변을 생성한다.
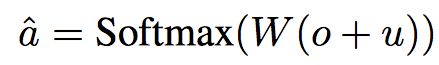
기본 구조는 이러하다. 즉, 답을 구할 때 쓰는 W 하나와
embedding matrix 3개 (입력, 출력 메모리, query)를 훈련으로 얻어낸다.
이 내용을 몇개 stacking 해보면 얻을 수 있는 것이 그림 (b)에 있는 내용이다.
Stacked memory networks
여러 개 layer를 쌓았을 때, weight을 묶어서 처리할 수 있다. 본 논문에서는 2가지 방식을 제안한다.
- Adjacent: 근접한 녀석을 묶는 다는 것이다. 즉, 현재 layer의 출력 메모리 embedding \(C^{k}\)와 상위 layer의 입력 메모리 embedding \(A^{k+1}\)를 같은 값으로 사용하는 것이다.
- Layer-wise(RNN-like): 모든 layer의 같은 동작을 하는 녀석들을 같은 값으로 사용하는 것이다. 이렇게 될 경우에 RNN과 같은 구조라고 볼 수 있다. 잠깐 생객해보면, (b)를 90도 눕혀서 보면 RNN 처럼 볼 수 있다. query가 올라가는 path를 hidden으로 보면 비슷하다고 볼 수 있으려나..
이 중에 본 논문에서는 adjacent 방식을 사용했다. 아무래도 이 방식이 조금 더 성능 향상에 도움이 되는 듯.
그 외의 detail
BoW 와 position encoding
위에서 간단하게 언급이 나왔던 \(m_i\)와 \(c_i\)를 어떻게 만드느냐에 대한 내용이다. \(x_{ij}\)는 i번째 문장의 j번째 단어를 의미한다.
BoW
간단하게 한 문장 내의 모든 word에 대한 vector를 모두 더하는 것이다.
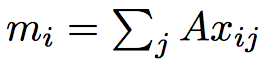
이렇게 되면 문제점은 word간의 위치 정보는 사라진다는 것이 단점이다.
이러한 단점을 보완하기 위해서 제안한 방식이 position encoding이다.
Position encoding
수식을 보면알겠지만, word의 위치에 따라 다른 scale을 붙여서 \(m_i\)를 생성한다.
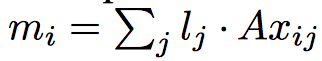
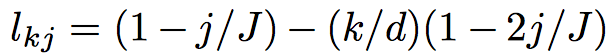
그런데 scale인 \(l_j\) 가 vector를 가지게 되고, 이걸 element-wise product을 통해서 값을 얻는다.
실제로 \(l_j\)는 아래와 같은 형태의 값을 가지게 된다.
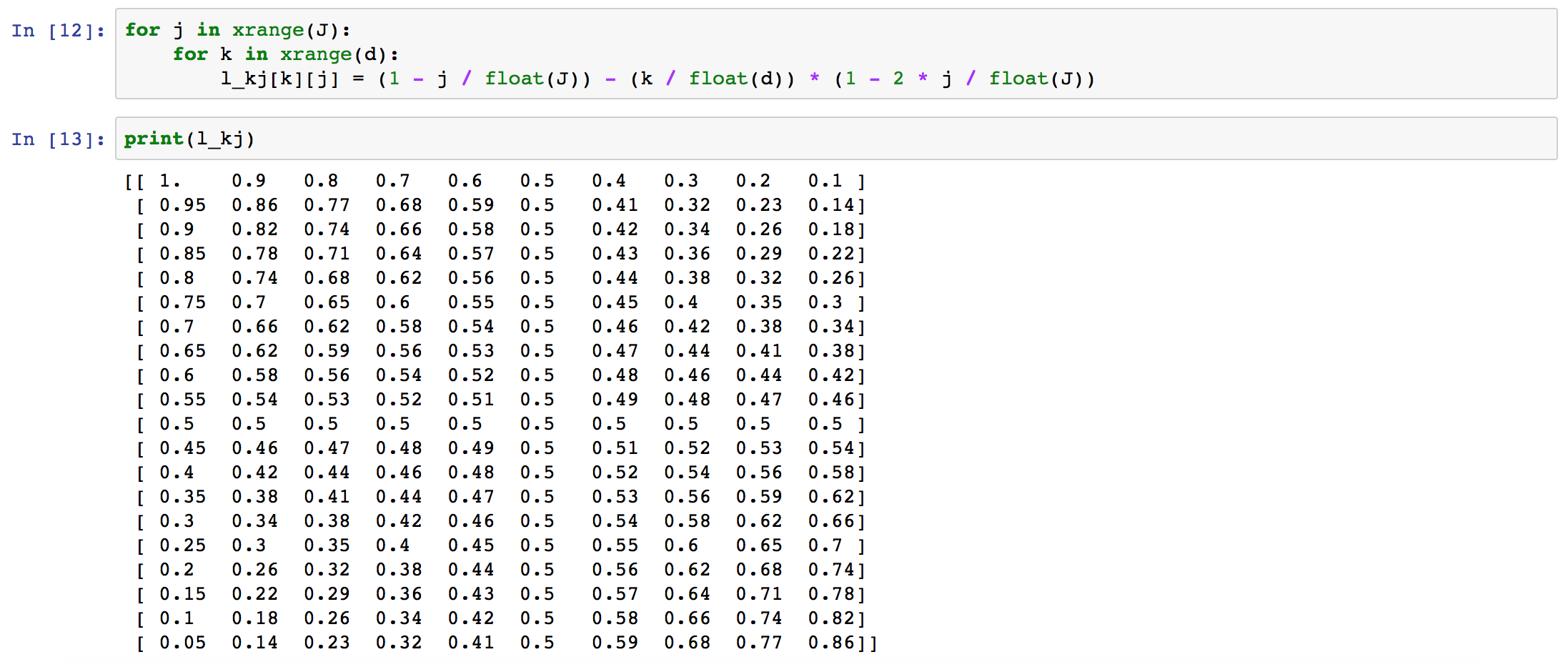
symmetric 성질을 가지고 있으며 word의 위치에 따라서 각각 \(m_i\)에 다른 가중치로 vector 영향을 주게 된다.
Temporal encoding
실제로 워드 단위의 위치도 중요하지만 문장의 순서도 중요하게 된다.
예시에서 나온 sam의 위치를 찾는 질문을 보면 문장의 순서에 답이 영향을 받기 때문이다.
따라서 이러한 문장별, weight을 주기 위해서 \(T_A(i)\) vector 를 추가적으로 \(m_i\)를 구할 때 넣는다.
다만, 여기서는 position encoding과 달리 정해진 방식으로 하는 것이 아니라,
task별로 문장 순서의 중요도가 달라지기 때문에 이 부분은 훈련을 통해서 획득한다.
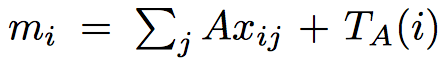
Injecting random noise
여전히 모르겠다.
Linear start
훈련 trick 중에 하나인데, 초반에는 softmax를 뺀 상태에서 훈련을 하다가
어느정도 훈련이 끝난 상태에서 softmax를 추가해서 사용하는 방법이다.
실제로 softmax에는 trainable parameter가 존재하지 않기 때문에 중간에 삽입하더라도
모델이 심각하게 영향을 받거나 하진 않겠으나, 그럼애도 훈련받는 나머지 parameter들은 영향을 받는다.
왜 좋은지는 모르겠으나 (아직 설명을 못찾음)
실험 결과를 보면 LS를 적용했을 때 조금 더 성능이 향상된 것으로 나타나는 것으로 소개하고 있다.
joint
task를 보면 bAbI에서도 여러가지가 있는데 best 성능은 각 task별 별도 훈련을 하는 것이다.
그런데 joint라 함은, 이러한 task를 모두 모아서 하나의 모델을 구성하여 inference했을 때의 결과를 의미한다.
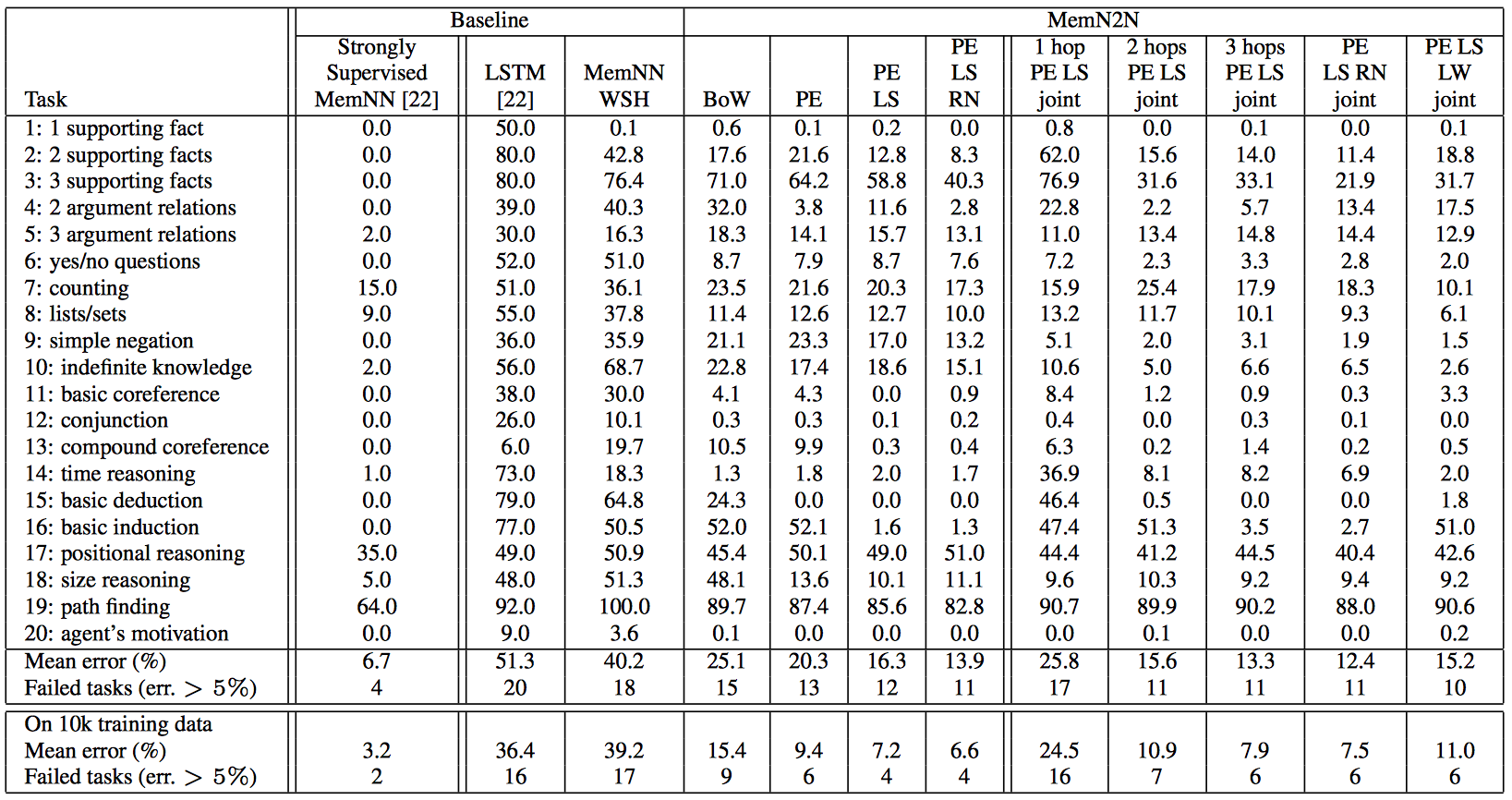
성능은?
아래 그래프를 보면 알 수 있을텐데,
task별 훈련했을 때가 가장 결과가 좋고,
Bow보단 PE가 좋고,
LS를 적용했을 때 성능이 올라가고,
RN을 넣으면 조금 더 향상된다.
정리
NTM보다 조금은 더 직관적인 구조를 가지고 있다.
(적어도 TM 자체도 생소한 나에게는 그렇다.)
하지만 아직까지는 word 하나에 대해서 결과를 뽑는 것 외에는 확장의 방안은… 좀 두고 봐야할 것 같다.
다른 응용예가 있는데 그 안에 참고할만한 것이 있을 수도 있고…
reasoning하는데 하나의 예시로 도움이 될만하긴 한데,
아직 뭔가 좀 더 필요해보이긴 하다.
Keras로 한번 구현해보면 좋을 것 같다.
변형된 형태의 MemNN은 Keras example에 구현되어 있다.
링크는…
keras/babi_memnn.py at master · fchollet/keras · GitHub